MIT6.824 分布式系统实验
LAB1 mapreduce
mapreduce中包含了两个角色,coordinator和worker,其中,前者掌管任务的分发和回收,后者执行任务。mapreduce分为两个阶段,map阶段和reduce阶段。
map阶段对应的是map任务。coordinator将会把任务分成多个部分,例如,有多个文件待处理,则每个文件的处理是一个任务。coordinator根据待处理文件生成多个任务,将这些任务用available管道暂存,供worker取用。worker将任务完成之后,需要告知coordinator,coordinator需要记录任务的状态。为了标识任务,每个任务需要有唯一的taskId。coordinator可以用taskId为key的map来存储所有task,worker完成一个task之后,这个task就没有必要保存,coordinator可以从map中删除该task。coordinator存储未完成的task,除了供worker比对之外,还可以用来重新分发超时的任务。worker调用coordinator的applyForTask函数,来从avaliable队列中得到新的任务。在map阶段,worker收到任务后会调用mapf函数,这个函数是用户传入的参数,指向任务的具体执行过程。对mapf的执行结果,worker根据reduce的个数,将执行结果hash成reduce份。例如,对于wordcount任务,每个文件中的词的统计数量将根据词分为reduce份,保存在reduce个文件中。
reduce阶段对应的是reduce任务。coordinator将生成reduce个新的任务,每个任务处理一个hash桶中的内容。同样用available管道供worker取用。当然,这时worker只需要知道自己取到的是第几个hash桶对应的reduce任务,即可通过共享文件和统一的文件命名规则获取到此时需要处理的文件。根据用户reducef函数的输入,worker将输入文件中的内容排序之后,将相同key的value存储成数组,输入reducef函数处理。
值得探讨的点:
worker通知coordinator任务完成:worker对任务完成的通知可以不必发一个新的包,因为worker每次完成任务的同时都会立即向coordinator请求新的任务,因此可以在请求包中附送上一个已经完成的taskId。coordinator经过比对taskId和workerId确认无误之后,在分发新任务之前就可以处理旧的已完成任务。
超时任务检测:有两种选择,1是worker接收任务之后定时发心跳包,但是这种方式较为繁琐。另一种是coordinator定时检查,task的map中对每个task维护一个ddl,若当前时刻已经超过了ddl时间,就视为超时。
available管道初始化容量:不初始化容量的话,管道会阻塞。
任务结果文件重命名:worker处理阶段,为了防止其他worker也在处理这一文件导致的写冲突,会将处理结果文件命名中加上workerId,但reduce阶段不需要知道map结果是由哪个worker生成的,因此coordinator确认任务完成后会对结果文件重新命名,去掉workerId的标记。reduce阶段同理。

LAB2 raft
raft是一个分布式共识算法。分为领导选举【Leader election】、日志复制【Log replication】和安全【Safety】。
在一个raft集群中,server总是在三种状态之间转换,follower、candidate、leader,且保证任何时刻系统中最多只有一个leader。系统将时间划分为多个term,term顺序递增,candidate进行选举的时候会先将自身的term加一,表示自己认为已经可以开始新的term了。在一个term内的稳定状态下,raft集群中只有一个leader,其余的server是follower,系统所处term的切换意味着leader的切换。leader定时向其余服务器发送一个heart beat心跳信息,表示自己仍然存活,此外,接收外界对raft系统的数据请求,提供对外服务,生成日志条目,并且将日志条目复制给其他的follower,以此实现数据的多存储;follower接受leader发送的heart beat,确认当前系统存在leader,并且接收leader发来的日志条目副本,更新本地的日志。

【Leader election】若follower的heart beat超时,即,在一段时间内都没有收到leader发来的heart beat。此时,这台follower认为leader已经挂掉,于是自动转化为candidate状态,开始竞选成为新一期的leader。candidate将自身的term加一,投票给自己,同时向所有server发送requestVote的请求,对于收到requestVote请求的服务器来说,只要它们在这个term没有投出票,则投给这个candidate,换句话说,一个server在一个term只能投一次票。在一轮投票中,若所得票数大于总服务器数量的一半,则赢得选举,成为本期leader,同时立即发送一条heart beat宣布上任,系统回到稳定状态。同一时刻允许同时存在多个candidate,此时可能会出现选票平分的情况,这时无法选出新的leader,candidate将重新发起投票,并且term再加一。重新投票将会影响系统的性能,为了减小同时出现多个candidate的可能性,每台server的heart beat超时时间(等待heart beat的时间)将设置为一个区间范围内的随机数。一般要求:heart beat时间<<选举超时时间<<平均故障时间。
由于raft集群的server总是在三种状态之间切换,不同状态执行不同的任务,因此将使用状态机来实现。server之间互相发送的包是心跳包和requestVote包以及它们的reply。
主线任务
leader:【发送心跳包给follower和candidate,收到不合法的心跳则拒收】向集群中其他所有成员定时发送heart beat,确认存活,同时接收其他成员反馈的reply信息。对于reply信息,有多种情况:
- 域名ess = true:成员承认本leader;
- 域名ess = false:成员拒绝承认本leader。原因是该成员的term>域名,本leader的任期已过,集群已经在新的term了。于是这台机器退位,降级为follower,并更新自身的term等信息,保持与集群同步。
follower:【从leader接收心跳包,从candidate接收requestVote包】
- 接收投票要求
- 如果投票的term大于自己,说明有人发现leader挂了,在发起新一轮的投票,投票,同时视为收到了心跳;
- 否则,拒绝投票,并且告诉通过域名告知candidate本机认为当前所处的term;
- 接收心跳:重置心跳超时计时器;
- 检查是否心跳超时:若超时,成为candidate,并且立即发起投票;
- 接收投票要求
candidate:【从leader接收心跳,发送requestVote包给follower和其他candidate,从其他candidate接收requestVote包】
发起投票。对于投票结果:
- 若超过半数同意,则立即成为leader并且执行leader任务;
- 若有人拒绝:查看域名,如果域名>=自己,说明是自己out了,降级为follower,取消本轮投票;否则就是单纯的不投我,那就算了;
检查投票是否超时,若超时,重新发起投票;
接收心跳,如果在投票过程中收到term>=自己的心跳,说明现在已经有leader了,降级到follower状态,取消本轮投票。
关于投票取消的时候可能发生的异常讨论
follower同意投票的同时,将term更新,立即视为进入了新的term并且将这个candidate视为当前term的leader,这是没有问题的。如果candidate选举成功,显然是没问题的;如果candidate选举不成功,即,取消投票,有以下情况:收到域名>=域名的选举回复,说明系统正在试图开启更大的term;收到term>=自己的心跳,说明当前系统中正处于更大的term,并且已经处于有leader的稳定状态。不论是试图开启还是已经达到,当这个更大的term达到稳定的状态时,其leader会发送心跳,心跳的term大于candidate的term,投票给candidate的server不会拒绝这些心跳,并且会立即响应进入新的term,从前的错误投票在新的term下毫无影响。
附:检测和修复data race https://域名/golang/data-races/
——————————————
(重构)
对于一台server,需要做的事情有三个方面:选举、日志复制、apply。其中,选举和apply两项是所有server都主动进行的,因此在初始化的时候使用两个goroutine来控制,日志复制应该是由client调用start来控制进行的。
timeout一直在倒计时,一旦超出了倒计时就称为candidate开始选举,倒计时期间,可能由于收到leader或者任期更大的server的消息而reset倒计时。
logApplier不断地推动lastApplied追上commitIndex,通过发送ApplyMsg给applyCh通道接口来apply日志,如果已经两者已经一致了,就wait直到有新的commit。如何检查有新的commit呢?可以使用域名条件变量,等commitIndex更新的时候用broadcast唤醒这个cond,从而疏通堵塞。
附: 关于域名 https://域名/tech/2019/06/15/域名
【选举】
投票条件:
- 候选人最后一条Log条目的任期号大于本地最后一条Log条目的任期号;
- 或者,候选人最后一条Log条目的任期号等于本地最后一条Log条目的任期号,且候选人的Log记录长度大于等于本地Log记录的长度
becomeCandidate时,立即开始选举,当然,这时候需要一些前序步骤:将term++标识进入了新的term,将votedfor置为me表示投票给自己了。
选举方:选举过程需要一个“得票数”的变量votesRcvd来记录已得票数(在分布式系统中,它的增加需要原子操作,因此用一个锁域名锁来保护),此外,还要用一个finish变量来确定已经做出回答的server有多少。每当得到一枚票,就唤醒(broadcast)一次cond锁,堵塞疏通,做出“继续等待/处理最终票数/直接return”的选择。其中,继续等待是当票数不够一半,但还有server没有做出回复的时候。处理最终票数是剩余情况。直接return比较特殊,因为可能在等待得票的过程中,本candidate已经不是candidate了,可能降级为follower了。处理最终票数就很简单了,如果够一半就升级为leader(开始心跳goroutine),不够就变成follower(此时是因为所有server都已经做出了回复所以开始处理最终票数的),处理最终票数的过程中,要通过判断和加锁的方式,确保本candidate仍然是candidate,且当前任期和得票的任期一样。
接待员(中间函数):构造args和reply,调用投票方的投票函数。对返回结果,只在voteGranted为true的时候返回true,否则返回false,如果域名更大,就令candidate降级为follower。同时,在处理期间也要保证本candidate是candidate的时候才有必要继续进行,但继续进行的时候,非必要不得对candidate加锁,否则容易形成死锁。
投票方:先检查域名,如果比自己大,那就先承认一下自己的follower地位, 如果域名比自己小,那就voteGranted置为false,让选举方承认自己follower的地位,并且返回,没必要再理会这次选举。继续处理的是域名>=自己的情况。如果还没投,或者已经投给了这个candidate,并且term相同的话选举方log更长,那就投给选举方,并且reset选举超时计时器。否则不投。简而言之,投票要检查term,term相等的话看log是不是新于自己,以及票是不是已经投出去了。
设计技巧:
- 将单个询问、处理回复和分发、回收分为两个过程。前者是接待员,为单个投票方提供单个接待服务,后者是总管,给各个投票方分配出各自的接待员。
- 尽量不加锁,或者锁粒度尽可能小,在处理的时候判断一下是不是状态还未过时。
【日志复制】
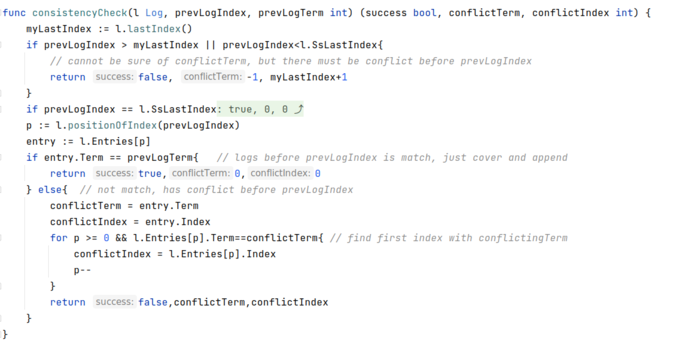
接待员(发送方/中间函数):取出目标server对应的nextIndex和matchIndex。如果nextIndex,即即将发送的entries的开始位置,<=snapshotLastIndex,就是已经被压缩了,那就将snapshot发送给目标server,返回。如果nextIndex在log里,就构造AppendEntriesArgs,把nextIndex后面所有的entries全发送过去,这时,要附带nextIndex-1这一条的index和term,用来给目标server做一致性检查。对于返回值,首先检查term判断是否本leader需要降级为follower,然后再判断是否成功。如果成功,就更新nextIndex和matchIndex,再看看需不需要commit。如果不成功,那就是一致性检查出问题了,找到冲突点,重新执行接待任务。
快速回退法: 发生冲突的时候,让follower返回足够的信息给leader,这样leader可以以term为单位来回退,而不用每次只回退一条log条目,因此当log不匹配的时候,leader只需要在每个不同的term发送一条appendEntries,这是一种加速策略。
冲突点回溯:找到域名logTerm的第一条log的index,就是目前看来的冲突index。不会往之前的term找,因为无法确定那里是不是冲突了。这个冲突index可能会有点悲观,这里会增加网络负载,可以优化。
设计技巧:
- matchIndex只在发送成功的时候更新,并且是为了commit设置的。follower的commitIndex始终是随着AppendEntriesArgs带来的leader的commitIndex更新的,自己不能主动判断更新。另,commit的时候会唤醒applyCond。
- nextIndex总是很乐观的,靠一致性检查和冲突点回溯来防止错误。
- 一条log entry的index和它在log中的下标不是同一个东西。
- 对log的操作可能很多,设计一个log类来专门管理这些操作,像cmu数据库一样写一些基本的常用操作函数。
- 向管道中塞东西,可能会发生堵塞,因此要使用goroutine。例如go 域名yCh<-msg
- appendNewentry时的index
关于日志复制时可能出现的异常情况讨论
如果leader正常工作,raft系统中不会出现什么问题,follower只需要接收leader发来的日志信息,将log的状态与leader的log状态靠齐即可。
一个旧leader故障之后,新的leader是否可以使系统达到一致?
假设现在系统中有三台机器,S1,S2和S3,其中S3是旧的leader,且系统此刻是一致的。S3可能引发不一致的故障时刻有三种:
- 将新条目添加到本地log之后立即故障:根据多数选举的规则,S1和S2中可以出现新的leader,系统继续服务。
- 将新条目添加到S1之后故障:S1可以成为leader,系统继续服务,S1会将这条条目传递给其他机器并且提交。
- 将新条目添加到S1并且提交之后故障:同上。
因此,旧leader S3故障之后,剩下的团体也可以正常服务。如果此时旧leader重新与集群建立了联系,系统将会如何?
不论中间经过了多少个term,假设现在的leader是S1,旧leader是S3,S3重新加入集群的时候,首先S3肯定会降级为follower,如果S3可以立即被选举为leader,那么就可以视为S3没有发生过故障。S1会发送新条目给S3的时候,S3会进行不一致性检查,经过多次发送并尝试append条目,S1会令S3的log状态与自己的达成一致。
关于已经commit的log是否会丢失的进一步讨论
假设当前leader是S3。已知leader选举,当term一致的时候,只能给log长于自己的投选举票。那么只有log长于其中超过半数机器的机器可以成为leader。已知leader永远不会丢弃自己已有的log,那么存在于leader中的被commit的log肯定不会被丢弃。丢弃的情况只会是一条log被大多数机器记录,但leader没有记录。
假设该log的index是i1,term是t1。根据log append的连续性,S3至多接收到i1-1之后就没有接收到t1的其他任何log了。进一步地,由于i1被保留到了S3入选的term,因此t1之后的leader都有i1记录,因此S3至多接收到i1-1之后就再也没有收到到选举为止的其他任何log了。在这种情况下,还要保证经历了所有的term(才能term与其他选举者一致),即使之后的所有term都不再append条目到任何机器上,那也有大多数机器比S3多了i1这条log,S3不可能选举成功。推出矛盾,因此commit的log不会丢失。
【persist】
persist类是raft类中的一个成员。其作用应该是为了保存state信息和snapshot信息,state信息包括currentTerm,votedFor,log。只有这三者需要被持久化存储,log是唯一记录了应用程序状态的地方,其中存储的一系列操作是唯一能在断电重启之后用来重建应用程序状态的信息;votedfor和currenterm是为了保证每个任期最多只有一个leader。其他的状态,例如lastApplied和commitIndex都可以通过leader和follower之间的交流来重新获得。
【snapshot】
每个server会自己创建自己的snapshot,也会接受并install leader发送的snapshot(这发生在日志同步的时候nextIndex<=ssLastshot时)。只有leader可以让其他server install自己的snapshot,这和只有leader可以让其他server appendEntries一样,因此,发送处理和接收处理之前都必须check发送方的leader身份,并且可以以此来代替加锁。
收到installSnapshot和收到AppendEntries类似,都需要有检查leader身份,确认自己follower身份和reset election timer等操作。将得到的snapshot发送到applyCh即可。
假死问题:由于网络原因导致的心跳超时,认为leader已死,但其实leader还活着。
脑裂问题:指的是分布式集群系统中由于网络故障等原因,选举出了两个leader,集群分裂成两个集群。出现脑裂问题的原因是分布式算法中没有考虑过半机制。脑裂问题对分布式系统是致命的,两个集群同时对外提供服务,会出现各种不一致问题,如果两个集群突然可以联通了,将不得不面对数据合并、数据冲突的解决等问题。
为了解决脑裂问题,通常有四种做法:
- zookeeper和raft中使用的过半原则;
- 添加心跳线。集群中采取多种通信方式,防止一种通信方式失效导致集群中的节点无法通信,比如原来只有一条心跳线路,此时若断开,则判断对方已死亡,若有两条心跳线,一条断开,另一条仍然可以收发心跳,保证集群服务正常运行,备用线路与主线路可以互相监测,正常情况下备用线路为了节约资源而不起作。
- 使用磁盘锁的形式,保证集群中只能有一个Leader获取磁盘锁,对外提供服务,避免数据错乱发生。但是,也会存在一个问题,若该Leader节点宕机,则不能主动释放锁,那么其他的Follower就永远获取不了共享资源。于是有人在HA中设计了"智能"锁。正在服务的一方只有在发现心跳线全部断开(察觉不到对端)时才启用磁盘锁。平时就不上锁了。
- 仲裁机制。比如提供一个参考的IP地址,心跳机制断开时,节点各自ping一下参考IP,如果ping不通,那么表示该节点网络已经出现问题,则该节点需要自行退出争抢资源,释放占有的共享资源,将服务的提供功能让给功能更全面的节点。

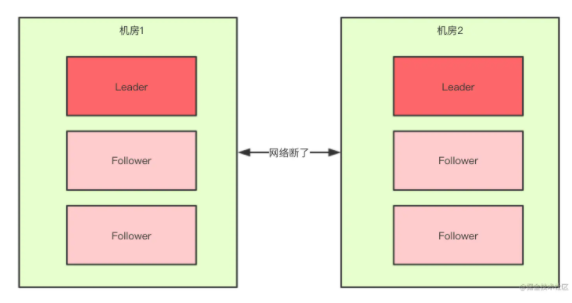
过半原则:根据鸽巢原理,raft中任意一个操作都需要过半的服务器的认同,这样能保证始终只有一个leader。此外,服务器通常选择奇数台机器部署,这样可以用较少的机器实现相同的集群容忍度。
快速领导者选举算法:在选举的过程中进行过半验证,这样不需要等待所有server都认同,速度比较快。
Lab3 KV-raft
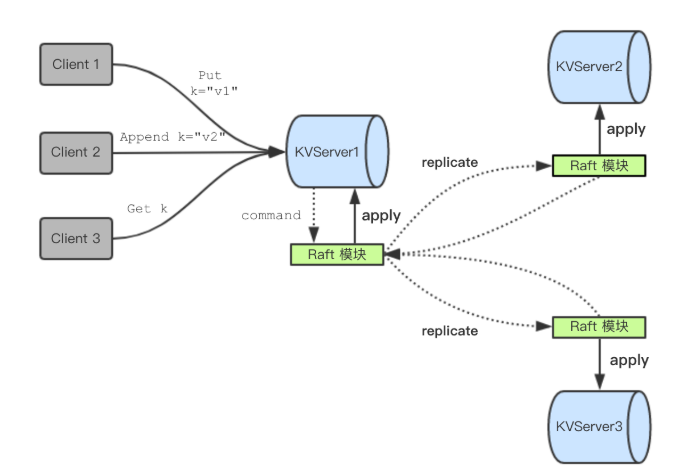
在此,从一个比lab2更高层次的角度看待分布式系统。lab2中的raft是用于机器之间互相沟通形成一致的log和state,但机器之间并不关心log中存储的command是什么,因此全部使用interface{}作为command的接口。lab3中,我们要实现的是client调用Get()、Append()、Put(),server通过raft达成集群内的一致,然后将raft apply的command正式执行。raft系统在这一过程中,只起到了一致性的作用,是命令的被调用和真正执行之间的一层。
这里需要注意的是线性一致性,为了实现这一点,给command递增的index(由raft调用start后返回),使用一个map记录每个client最近最后一个被执行command的index以及执行结果,由此可以推测出command序列执行到哪一条了,防止重复执行。
另外,由于raft系统在start和apply之间需要一定的时间,因此,客户端调用读写函数,读写函数调用start通知raft集群之后,注册一个index对应的待相应result channel,存储在以index为key的map中。当raft系统达成一致,apply这条命令的时候,从apply函数调用真正的读写过程,执行结果push到index对应的channel中。于是,客户端调用的读写函数只需要直接去result channel中取出这条命令的执行结果。这样做非常的简洁流畅,用channel阻塞的时间来等待raft系统一致、apply执行读写。
关于start和apply之间leader被更换的讨论:
一条command,在其start和apply中间,可能raft系统已经更换了leader,对于新的leader来说,它没有为这条command创建channel(start不是通过新leader进行的),试图将result放入channel的时候会失败,导致直接返回。然而,旧leader虽然降级为follower,但仍然会对这条apply,因此即使更换leader也没关系,但需要注意的是,从channel取出result的时候,就不必判断这个机器是不是leader了,只要在start的时候判断了就可以了。
关于command的index是否会发生变化的讨论:
command的index是由start调用的时候,leader的log中当前log最后一条entry的index+1决定的顺序index,如果这条command的entry被覆盖,那就会超时,client将更换server重新执行,如果没有被覆盖,将会保持这个index。
如果command的entry被覆盖了,且这个index对应的map中仍然有channel在等待答案(发生于leader降级,被新的leader清除了index对应位置,并且没有覆盖,leader又当选为leader,并建立了新的index位置),那么将会发生不匹配,因此,应该在从channel中取出result的时候检查op是否是在等待的那个。
如果op正好与在等待的那个一致,但是seq又不是那个呢?没有关系,只要执行内容一致就可以了。client中等待之后那条op结果的timer会超时,重新执行之后那条op。
B部分是压缩,kv中有一个变量maxraftState限制了log的长度,若即将超过这个长度,就对log进行压缩。同时,kv的data和peocessed也应该被持久化存储。
此外,LAB3可以使用init函数完成logger注册,并记录。当然,这不是必需的。
关于golang中的init函数
golang里的main函数是程序的入口函数,main函数返回后,程序也就结束了。golang还有另外一个特殊的函数init函数,先于main函数执行,实现包级别的一些初始化操作。
init函数的主要作用:
- 初始化不能采用初始化表达式初始化的变量。
- 程序运行前的注册。
- 实现域名功能。
- 其他
init函数的主要特点:
- init函数先于main函数自动执行,不能被其他函数调用;
- init函数没有输入参数、返回值;
- 每个包可以有多个init函数;
- 包的每个源文件也可以有多个init函数,这点比较特殊;
- 同一个包的init执行顺序,golang没有明确定义,编程时要注意程序不要依赖这个执行顺序。
- 不同包的init函数按照包导入的依赖关系决定执行顺序。