剖析虚幻渲染体系(13)- RHI补充篇:现代图形API之奥义与指南
-
13.1 本篇概述
- 13.1.1 本篇内容
- 13.1.2 概念总览
- 13.1.3 现代图形API特点
-
13.2 设备上下文
- 13.2.1 启动流程
- 13.2.2 Device
- 13.2.3 Swapchain
-
13.3 管线资源
- 13.3.1 Command
- 13.3.2 Render Pass
- 13.3.3 Texture, Shader
- 13.3.4 Shader Binding
- 13.3.5 Heap, Buffer
- 13.3.6 Fence, Barrier, Semaphore
-
13.4 管线机制
-
13.4.1 Resource Management
- 13.4.1.1 Resource Allocation
- 13.4.1.2 Resource Update
- 13.4.2 Pipeline State Object
-
13.4.3 Synchronization
- 13.4.3.1 Barrier
- 13.4.3.2 Fence
- 13.4.3.3 Pipeline Barrier
- 13.4.4 Parallel Command Recording
- 13.4.5 Multi Queue
-
13.4.6 其它管线技术
- 13.4.6.1 Wave
- 13.4.6.2 ExecuteIndirect
- 13.4.6.3 Predication
- 13.4.6.4 UAV Overlap
- 13.4.6.5 Multi GPU
-
13.4.1 Resource Management
-
13.5 综合应用
- 13.5.1 Rendering Hardware Interface
- 13.5.2 Multithreaded Rendering
- 13.5.3 Frame Graph
- 13.5.4 GPU-Driven Rendering Pipeline
- 13.5.5 Performance Monitor
-
13.6 本篇总结
- 13.6.1 Vulkan贡献者名单
- 13.6.2 本篇思考
- 特别说明
- 参考文献
13.1 本篇概述
13.1.1 本篇内容
本篇是RHI篇章的补充篇,将详细且深入地阐述现代图形API的特点、原理、机制和优化技巧。更具体地,本篇主要阐述以下内容:
- 现代图形API的基础概念。
- 现代图形API的特性。
- 现代图形API的使用方式。
- 现代图形API的原理和机制。
- 现代图形API的优化建议。
此文所述的现代图形API指DirectX12、Vulkan、Metal等,而不包含DirectX11和Open GL(ES),但也不完全排除后者的内容。
由于UE的RHI封装以DirectX为主,所以此文也以DirectX作为主视角,Vulkan、Metal等作为辅视角。
13.1.2 概念总览
我们都知道,现存的API有很多种(下表),它们各具特点,自成体系,涉及了众多不同但又相似的概念。
| 图形API | 适用系统 | 着色语言 |
|---|---|---|
| DirectX | Windows、XBox | HLSL(High Level Shading Language) |
| Vulkan | 跨平台 | SPIR-V |
| Metal | iOS、MacOS | MSL(Metal Shading Language) |
| OpenGL | 跨平台 | GLSL(OpenGL Shading Language) |
| OpenGL ES | 移动端 | ES GLSL |
下面是它们涉及的概念和名词的对照表:
| DirectX | Vulkan | OpenGL(ES) | Metal |
|---|---|---|---|
| texture | image | texture and render buffer | texture |
| render target | color attachments | color attachments | color attachments or render target |
| command list | command buffer | part of context, display list, NV_command_list | command buffer |
| command list | secondary command buffer | - | parallel command encoder |
| command list bundle | - | light-weight display list | indirect command buffer |
| command allocator | command pool | part of context | command queue |
| command queue | queue | part of context | command queue |
| copy queue | transfer queue | glBlitFramebuffer() | blit command encoder |
| copy engine | transfer engine | - | blit engine |
| predication | conditional rendering | conditional rendering | - |
| depth / stencil view | depth / stencil attachment | depth attachment and stencil attachment | depth attachment and stencil attachment, depth render target and stencil render target |
| render target view, depth / stencil view, shader resource view, unordered access view | image view | texture view | texture view |
| typed buffer SRV, typed buffer UAV | buffer view, texel buffer | texture buffer | texture buffer |
| constant buffer views (CBV) | uniform buffer | uniform buffer | buffer in constant address space |
| rasterizer order view (ROV) | fragment shader interlock | GL_ARB_fragment_shader_interlock | raster order group |
| raw or structured buffer UAV | storage buffer | shader storage buffer | buffer in device address space |
| descriptor | descriptor | - | argument |
| descriptor heap | descriptor pool | - | heap |
| descriptor table | descriptor set | - | argument buffer |
| heap | device memory | - | placement heap |
| - | subpass | pixel local storage | programmable blending |
| split barrier | event | - | - |
| ID3D12Fence::SetEventOnCompletion | fence | fence, sync | completed handler, -[MTLComandBuffer waitUntilComplete] |
| resource barrier | pipeline barrier, memory barrier | texture barrier, memory barrier | texture barrier, memory barrier |
| fence | semaphore | fence, sync | fence, event |
| D3D12 fence | timeline semaphore | - | event |
| pixel shader | fragment shader | fragment shader | fragment shader or fragment function |
| hull shader | tessellation control shader | tessellation control shader | tessellation compute kernel |
| domain shader | tessellation evaluation shader | tessellation evaluation shader | post-tessellation vertex shader |
| collection of resources | fragmentbuffer | fragment object | - |
| pool | heap | - | - |
| heap type, CPU page property | memory type | automatically managerd, texture storage hint, buffer storage | storage mode, CPU cache mode |
| GPU virtual address | buffer device address | - | - |
| image layout, swizzle | image tiling | - | - |
| matching semantics | interface matching (in / out) | varying (removed in GLSL 域名) | - |
| thread, lane | invocation | invocation | thread, lane |
| threadgroup | workgroup | workgroup | threadgroup |
| wave, wavefront | subgroup | subgroup | SIMD-group, quadgroup |
| slice | layer | - | slice |
| device | logical device | context | device |
| multi-adapter device | device group | implicit(E.g. SLICrossFire) | peer group |
| adapter, node | physical device | - | device |
| view instancing | multiview rendering | multiview rendering | vertex amplification |
| resource state | image layout | - | - |
| pipeline state | pipeline | stage and program or program pipeline | pipeline state |
| root signature | pipeline layout | - | - |
| root parameter | descriptor set layout binding, push descriptor | - | argument in shader parameter list |
| resulting ID3DBlob from D3DCompileFromFile | shader module | shader object | shader library |
| shading rate image | shading rate attachment | - | rasterization rate map |
| tile | sparse block | sparse block | sparse tile |
| reserved resource(D12), tiled resource(D11) | sparse image | sparse texture | sparse texture |
| window | surface | HDC, GLXDrawable, EGLSurface | layer |
| swapchain | swapchain | Pairt of HDC, GLXDrawable, EGLSurface | layer |
| - | swapchain image | default framebuffer | drawable texture |
| stream-out | transform feedback | transform feedback | - |
从上表可知,Vulkan和OpenGL(ES)比较相似,但多了很多概念。Metal作为后起之秀,很多概念和DirectX相同,但部分又和Vulkan相同,相当于是前辈们的混合体。
对于Vulkan,涉及的概念、层级和数据交互关系如下图所示:
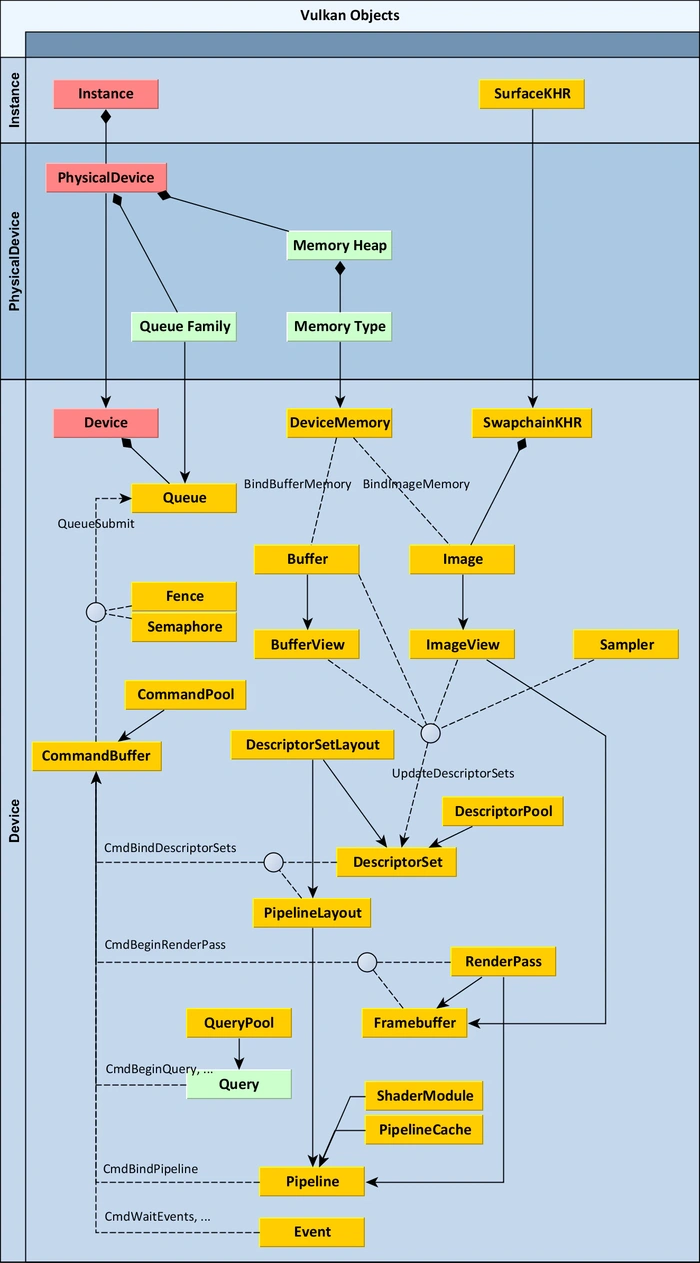
Vulkan概念和层级架构图。涉及了Instance、PhysicalDevice、Device等层级,每个层级的各个概念或资源之间存在错综复杂的引用、组合、转换、交互等关系。

Metal资源和概念框架图。
13.1.3 现代图形API特点
对于传统图形API(DirectX11及更早、OpenGL、OpenGL ES),GPU编程开销很大,主要表现在:
- 状态校验(State validation):
- 确认API标记和数据合法。
- 编码API状态到硬件状态。
- 着色器编译(Shader compilation):
- 运行时生成着色器机器码。
- 状态和着色器之间的交互。
- 发送工作到GPU(Sending work to GPU):
- 管理资源生命周期。
- 批处理渲染命令。
对于以上开销大的操作,传统图形API和现图形代API的描述如下:
| 阶段 | 频率 | 传统图形API | 现代图形API |
|---|---|---|---|
| 应用程序构建 | 一次 | - | 着色器编译 |
| 内容加载 | 少次 | - | 状态校验 |
| 绘制调用 | 1000次每帧 | 状态校验,着色器编译,发送工作到GPU | 发送工作到GPU |
以上可知,传统API将开销较大的状态校验、着色器编译和发送工作到GPU全部放到了运行时,而现代图形API将着色器编译放到了应用程序构建期间,而状态校验移至内容加载之时,只保留发送工作到GPU在绘制调用期间,从而极大减轻了运行时的工作负担。
现代图形API(DirectX12、Vulkan、Metal)和传统图形API的描述对照表如下:
| 现代图形API | 传统图形API |
|---|---|
| 基于对象的状态,没有全局状态。 | 单一的全局状态机。 |
| 所有的状态概念都放置到命令缓冲区中。 | 状态被绑定到单个上下文。 |
| 可以多线程编码,并且受驱动和硬件支持。 | 渲染操作只能被顺序执行。 |
| 可以精确、显式地操控GPU的内存和同步。 | GPU的内存和同步细节通常被驱动程序隐藏起来。 |
| 驱动程序没有运行时错误检测,但存在针对开发人员的验证层。 | 广泛的运行时错误检测。 |
相比OpenGL(ES)等传统API,Vulkan支持多线程,轻量化驱动层,可以精确地管控GPU内存、同步等资源,避免运行时创建和消耗资源堆,避免运行时校验,避免CPU和GPU的同步点,基于命令队列的机制,没有全局状态等等(下图)。

Vulkan拥有更轻量的驱动层,使得应用程序能够拥有更大的自由度控制GPU,也有更多的硬件性能。
图形API、驱动层、操作系统、内核层架构图。
Metal(右)比OpenGL(左)拥有更轻量的驱动层。

DirectX11驱动程序(上)和DirectX12应用程序(下)执行的工作对比图。
得益于Vulkan的先进设计理念,使得它的渲染性能更高,通常在CPU、GPU、带宽、能耗等指标都优于OpenGL。但如果是应用程序本身的CPU或者GPU负载高,则使用Vulkan的收益可能没有那么明显:

对于使用了传统API的渲染引擎,如果要迁移到现代图形API,潜在收益和工作量如下图所示:

从OpenGL(ES)迁移到现代图形API的成本和收益对比。横坐标是从OpenGL(ES)迁移其它图形API的工作量,纵坐标是潜在的性能收益。可见Vulkan和DirectX12的潜在收益比和工作量都高,而Metal次之。
部分GPU厂商(如NVidia)会共享OpenGL和Vulkan驱动,甚至在应用程序层,它们可以混合:

NV的OpenGL和Vulkan共享架构图。可以共享资源、工具箱,提升性能,提升可移植性,允许应用程序在最重要的地方增加Vulkan,获取了OpenGL即获取了Vulkan,减少驱动程序的开发工作量。
利用现代图形API,可以获得的潜在收益有:
- 更好地利用多核CPU。如多线程录制、多线程渲染、多队列、异步技术等。
- 更小的驱动层开销。
- 精确的内存和资源管理。
- 提供精确的多设备访问。
- 更多的Draw Call,更多的渲染细节。
- 更高的最小、最大、平均帧率。
- 更高效的GPU硬件使用。
- 更高效的集成GPU硬件使用。
- 降低系统功率。
- 允许新的架构设计,以前由于传统API的技术限制而认为是不可能的,如TBR。
13.2 设备上下文
13.2.1 启动流程
对大多数图形API而言,应用程序使用它们时都存在以下几个阶段:
stateDiagram-v2 [*] --> InitAPI InitAPI --> LoadingAssets LoadingAssets --> UpdatingAssets UpdatingAssets --> Presentation Presentation --> AppClosed AppClosed-->LoadingAssets:No AppClosed-->Destroy:Yes Destroy --> [*]- InitAPI:创建访问API内部工作所需的核心数据结构。
- LoadingAssets:创建数据结构需要加载的东西(如着色器),以描述图形管道,创建和填充命令缓冲区让GPU执行,并将资源发送到GPU的专用内存。
- UpdatingAssets:更新任何Uniform数据到着色器,执行应用程序级别的逻辑。
- Presentation:将命令缓冲区列表发送到命令队列,并呈现交换链。
- AppClosed:如果应用程序没有发送关闭命令,则重复LoadingAssets、UpdatingAssets、Presentation阶段,否则执行Destroy阶段。
- Destroy:等待GPU完成所有剩余工作,并销毁所有数据结构和句柄。
现代图形API启动流程。
后续章节将按照上面的步骤和阶段涉及的概念和机制进行阐述。
13.2.2 Device
初始化图形API阶段,涉及了Factory、Instance、Device等等概念,它们的概念在各个图形API的对照表如下:
| 概念 | UE | DirectX 12 | DirectX 11 | Vulkan | Metal | OpenGL |
|---|---|---|---|---|---|---|
| Entry Point | FDynamicRHI | IDXGIFactory4 | IDXGIFactory | vk::Instance | CAMetalLayer | Varies by OS |
| Physical Device | - | IDXGIAdapter1 | IDXGIAdapter | vk::PhysicalDevice | MTLDevice | glGetString(GL_VENDOR) |
| Logical Device | - | ID3D12Device | ID3D11Device | vk::Device | MTLDevice | - |
Entry Point(入口点)是应用程序的全局实例,通常一个应用程序只有一个入口点实例。用来保存全局数据、配置和状态。
Physical Device(物理设备)对应着硬件设备(显卡1、显卡2、集成显卡),可以查询重要的设备具体细节,如内存大小和特性支持。
Logical Device(逻辑设备)可以访问API的核心内部函数,比如创建纹理、缓冲区、队列、管道等图形数据结构,这种类型的数据结构在所有现代图形api中大部分是相同的,它们之间的变化很少。Vulkan和DirectX 12通过Logical Device创建内存数据结构来控制内存。
每个应用程序通常有且只有一个Entry Point,UE的Entry Point是FDynamicRHI的子类。每个Entry Point拥有1个或多个Physical Device,每个Physical Device拥有1个或多个Logical Device。
13.2.3 Swapchain
应用程序的后缓存和交换链根据不同的系统或图形API有所不同,涉及了以下概念:
| 概念 | UE | DirectX 12 | DirectX 11 | Vulkan | Metal | OpenGL |
|---|---|---|---|---|---|---|
| Window Surface | FRHIRenderTargetView | ID3D12Resource | ID3D11Texture2D | vk::Surface | CAMetalLayer | Varies by OS |
| Swapchain | - | IDXGISwapChain3 | IDXGISwapChain | vk::Swapchain | CAMetalDrawable | Varies by OS |
| Frame Buffer | FRHIRenderTargetView | ID3D12Resource | ID3D11RenderTargetView | vk::Framebuffer | MTLRenderPassDescriptor | GLuint |
在DirectX上,由于只有Windows / Xbox作为API的目标,最接近Surface(表面)的东西是从交换链接收到的纹理返回缓冲区。交换链接收窗口句柄,从那里DirectX驱动程序内部会创建一个Surface。对于Vulkan,需要以下几个步骤创建可呈现的窗口表面:

Vulkan WSI的步骤示意图。
由于MacOS和iOS窗口具有分层结构(hierarchical structure),其中应用程序包含一个视图(View),视图可以包含一个层(layer),在Metal中最接近Surface的东西是layer或包裹它的view。
Metal和OpenGL缺少交换链的概念,而把交换链留给了操作系统的窗口API。
DirectX 12和11没有明确的数据结构表明Frame Buffer,最接近的是Render Target View。
Swapchain(交换链)包含单缓冲、双缓冲、三缓冲,分别应对不同的情况。应用程序必须做显式的缓冲区旋转:
DirectX:IDXGISwapChain3::GetCurrentBackBufferIndex()
下面是对Swapchain的使用建议:
- 如果应用程序总是比vsync运行得慢,那么在交换链中使用1个Surface。
- 如果应用程序总是比vsync运行得快,那么在交换链中使用2个Surface,可以减少内存消耗。
- 如果应用程序有时比vsync运行得慢,那么在交换链中使用3个Surface,可以给应用程序提供最佳性能。

Vulkan交换链运行示意图。
13.3 管线资源
现代图形渲染管线涉及了复杂的流程、概念、资源、引用和数据流关系。(下图)

Vulkan渲染管线关系图。
13.3.1 Command
现代图形API的Command(命令)包含应用程序向GPU交互的所有操作,涉及了以下几种概念:
| 概念 | UE | DirectX 12 | DirectX 11 | Vulkan | Metal | OpenGL |
|---|---|---|---|---|---|---|
| Command Queue | - | ID3D12CommandQueue | ID3D11DeviceContext | vk::Queue | MTLCommandQueue | - |
| Command Allocator | - | ID3D12CommandAllocator | ID3D11DeviceContext | vk::CommandPool | MTLCommandQueue | - |
| Command Buffer | FRHICommandList | ID3D12GraphicsCommandList | ID3D11DeviceContext | vk::CommandBuffer | MTLRenderCommandEncoder | - |
| Command List | FRHICommandList | ID3D12CommandList[] | ID3D11CommandList | vk::SubmitInfo | MTLCommandBuffer | - |
Command Queue允许我们将任务加入队列给GPU执行。GPU是一种异步计算设备,需要让它一直处于繁忙状态,同时控制何时将项目添加到队列中。
Command Allocator允许创建Command Buffer,可以定义想要GPU执行的函数。Command Allocator数量上的建议是:
\[N_{录制线程} \times N_{缓冲帧} + N_{Bundle池} \]如果有数百个Command Allocator,是错误的做法。Command Allocator只会增加,意味着:
- 不能从分配器中回收内存。回收分配器将把它们增加到最坏情况下的大小。
- 最好将它们分配到命令列表中。
- 尽可能按大小分配池。
- 确保重用分配器/命令列表,不要每帧重新创建。
Command Buffer是一个异步计算单元,可以描述GPU执行的过程(例如绘制调用),将数据从CPU-GPU可访问的内存复制到GPU的专用内存,并动态设置图形管道的各个方面,比如当前的scissor。Vulkan的Command Buffer为了达到重用和精确的控制,有着复杂的状态和转换(即有限状态机):

Command List是一组被批量推送到GPU的Command Buffer。这样做是为了让GPU一直处于繁忙状态,从而减少CPU和GPU之间的同步。每个Command List严格地按照顺序执行。Command List可以调用次级Command List(Bundle、Secondary Command List)。这两级的Command List都可以被调用多次,但需要等待上一次提交完成。
下图是DX12的命令相关的概念构成的层级结构关系图:

对于相似的Command List或Allocator,尽量复用之:
当重置Command List或Allocator时,尽量保持它们引用的资源不变(没有销毁或新的分配)。
但如果数据很不相似,则销毁之,销毁之前必须释放内存。
为了更好的性能,在Command方面的建议如下:
-
对Command Buffer使用双缓冲、三缓冲。在CPU上填充下一个,而前一个仍然在GPU上执行。
-
拆分一帧到多个Command Buffer。更有规律的GPU工作提交,命令越早提交越少延时。
-
限制Command Buffer数量。比如每帧15~30个。
-
将多个Command Buffer批处理到一个提交调用中,限制提交次数。比如每帧每个队列5个。
-
控制Command Buffer的粒度。提交大量的工作,避免多次小量的工作。
-
记录帧的一部分,每帧提交一次。
-
在多个线程上并行记录多个Command Buffer。
-
大多数对象和数据(包含但不限于Descriptor、CB等内存数据)在GPU上使用时不会被图形API执行引用计数或版本控制。确保它们在GPU使用时保持生命周期和不被修改。可以和Command Buffer的双缓冲、三缓冲一起使用。
-
使用Ring Buffer存储动态数据。
13.3.2 Render Pass
| 概念 | UE | DirectX 12 | DirectX 11 | Vulkan | Metal | OpenGL |
|---|---|---|---|---|---|---|
| Render Pass | FRHIRenderPassInfo | BeginRenderPass, EndRenderPass | - | VkRenderPass | MTLRenderPassDescriptor | - |
| SubPass | FRHIRenderPassInfo | - | - | VkSubpassDescription | Programmable Blending | PLS |
绘制命令必须记录在Render Pass实例中,每个Render Pass实例定义了一组输入、输出图像资源,以便在渲染期间使用。

DirectX 12录制命令队列示意图。其中命令包含了资源、光栅化等类型。
现代移动GPU已经普遍支持TBR架构,为了更好地利用此架构特性,让Render Pass期间的数据保持在Tile缓存区内,便诞生了Subpass技术。利用Subpass技术可以显著降低带宽,提升渲染效率。更多请阅读域名 subpass和10.4.4.2 Subpass渲染。

Vulkan Render Pass内涉及的各类概念、资源及交互关系。
在OpenGL,采用Pixel Local Storage的技术来模拟Subpass。Metal则使用Programmable Blending(PB)来模拟Subpass机制(下图)。

上:传统的多Pass渲染延迟光照,多个GBuffer纹理会在GBuffer Pass和Lighting Pass期间来回传输于Tile Memeory和System Memory之间;下:利用Metal的PB技术,使得GBuffer数据在GBuffer Pass和Lighting Pass期间一直保持在Tile Memroy内。

Metal利用Render Pass的Store和Load标记精确地控制Framebuffer在Tile内,从而极大地降低读取和写入带宽。
创建和使用一个Render Pass的伪代码如下:
Start a render pass
// 以下代码会循环若干次
Bind all the resources
Descriptor set(s)
Vertex and Index buffers
Pipeline state
Modify dynamic state
Draw
End render pass
Vulkan的Render Pass使用建议:
- 即使是几个subpass组成一个小的Render Pass,也是好做法。
- Depth pre-pass, G-buffer render, lighting, post-process
- 依赖不是必定需要的。
- 多个阴影贴图通道产生多个输出。
- 把要做的任务重叠到Render Pass中。
- 优先使用load op clear而不是vkCmdClearAttachment。
- 优先使用渲染通道附件的最终布局,而不是明确的Barrier。
- 充分利用“don’t care”。
- 使用解析附件执行MSAA解析。
更多Render Pass相关的说明请阅读:域名 subpass和10.4.4.2 Subpass渲染。
13.3.3 Texture, Shader
| 概念 | UE | DirectX 12 | DirectX 11 | Vulkan | Metal | OpenGL |
|---|---|---|---|---|---|---|
| Texture | FRHITexture | ID3D12Resource | ID3D11Texture2D | vk::Image & vk::ImageView | MTLTexture | GLuint |
| Shader | FRHIShader | ID3DBlob | ID3D11VertexShader, ID3D11PixelShader | vk::ShaderModule | MTLLibrary | GLuint |
大多数现代图形api都有绑定数据结构,以便将Uniform Buffer和纹理连接到需要这些数据的图形管道。Metal的独特之处在于,可以在命令编码器中使用setVertexBuffer绑定Uniform,比Vulkan、DirectX 12和OpenGL更容易构建。
13.3.4 Shader Binding
| 概念 | UE | DirectX 12 | DirectX 11 | Vulkan | Metal | OpenGL |
|---|---|---|---|---|---|---|
| Shader Binding | FRHIUniformBuffer | ID3D12RootSignature | ID3D11DeviceContext::VSSetConstantBuffers(...) | vk::PipelineLayout & vk::DescriptorSet | [MTLRenderCommandEncoder setVertexBuffer: uniformBuffer] | GLint |
| Pipeline State | FGraphicsPipelineStateInitializer | ID3D12PipelineState | Various State Calls | vk::Pipeline | MTLRenderPipelineState | Various State Calls |
| Descriptor | - | D3D12_ROOT_DESCRIPTOR | - | VkDescriptorBufferInfo, VkDescriptorImageInfo | argument | - |
| Descriptor Heap | - | ID3D12DescriptorHeap | - | VkDescriptorPoolCreateInfo | heap | - |
| Descriptor Table | - | D3D12_ROOT_DESCRIPTOR_TABLE | - | VkDescriptorSetLayoutCreateInfo | argument buffer | - |
| Root Parameter | - | D3D12_ROOT_PARAMETER | - | VkDescriptorSetLayoutBinding | argument in shader parameter list | - |
| Root Signature | - | ID3D12RootSignature | - | VkPipelineLayoutCreateInfo | - | - |
Pipeline State(管线状态)是在执行光栅绘制调用、计算调度或射线跟踪调度时将要执行的内容的总体描述。DirectX 11和OpenGL没有专门的图形管道对象,而是在执行绘制调用之间使用调用来设置管道状态。
Root Signature(根签名)是定义着色器可以访问哪些类型的资源的对象,比如常量缓冲区、结构化缓冲区、采样器、纹理、结构化缓冲区等等(下图)。

具体地说,Root Signature可以设置3种类型的资源和数据:Descriptor Table、Descriptor、Constant Data。

DirectX 12根签名数据结构示意图。
这三种资源在CPU和GPU的消耗刚好相反,需权衡它们的使用:

Root Signature3种类型(Descriptor Table、Descriptor、Constant Data)在GPU内存获取消耗依次降低,但CPU消耗依次提升。
更具体地说,改变Table的指针消耗非常小(只是改变指针,没有同步开销),但改变Table的内容比较困难(处于使用中的Table内容无法被修改,没有自动重命名机制)。
因此,需要尽量控制Root Signature的大小,有效控制Shader可见范围,只在必要时才更新Root Signature数据。
Root Signature在DirectX 12上最大可达64 DWORD,可以包含数据(会占用很大存储空间)、Descriptor(2 DWORD)、指向Descriptor Table的指针(下图)。
Descriptor(描述符)是一小块数据,用来描述一个着色器资源(如缓冲区、缓冲区视图、图像视图、采样器或组合图像采样器)的参数,只是不透明数据(没有OS生命周期管理),是硬件代表的视图。

Descriptor的数据图例。
Descriptor被组织成Descriptor Table(描述符表),这些Descriptor Table在命令记录期间被绑定,以便在随后的绘图命令中使用。
每个Descriptor Table中内容的编排由Descriptor Table中的Layout(布局)决定,该布局决定哪些Descriptor可以存储在其中,管道可以使用的Descriptor Table或Root Parameter(根参数)的序列在Root Signature中指定。每个管道对象使用的Descriptor Table和Root Parameter有数量限制。
Descriptor Heap(描述符堆)是处理内存分配的对象,用于存储着色器引用的对象的描述。

Root Signature、Root Parameter、Descriptor Table、Descriptor Heap的关系。其中Root Signature存储着若干个Root Parameter实例,每个Root Parameter可以是Descriptor Table、UAV、SRV等对象,Root Parameter的内存内容存在了Descriptor Heap中。
DX12的根签名在GPU内部的交互示意图。其中Root Signature在所有Shader Stage中是共享的。
下面举个Vulkan Descriptor Set的使用示例。已知有以下3个Descriptor Set A、B、C:

通过以下C++代码绑定它们:
vkBeginCommandBuffer();
// ...
vkCmdBindPipeline(); // Binds shader
// 绑定Descriptor Set B和C, 其中C在序号0, B在序号2. A没有被绑定.
vkCmdBindDescriptorSets(firstSet = 0, pDescriptorSets = &descriptor_set_c);
vkCmdBindDescriptorSets(firstSet = 2, pDescriptorSets = &descriptor_set_b);
vkCmdDraw(); // or dispatch
// ...
vkEndCommandBuffer();
则经过上述代码绑定之后,Shader资源的绑定序号如下图所示:

对应的GLSL代码如下:
layout(set = 0, binding = 0) uniform sampler2D myTextureSampler;
layout(set = 0, binding = 2) uniform uniformBuffer0 {
float someData;
} ubo_0;
layout(set = 0, binding = 3) uniform uniformBuffer1 {
float moreData;
} ubo_1;
layout(set = 2, binding = 0) buffer storageBuffer {
float myResults;
} ssbo;
对于复杂的渲染场景,应用程序可以修改只有变化了的资源集,并且要保持资源绑定的更改越少越好。下面是渲染伪代码:
foreach (scene) {
vkCmdBindDescriptorSet(0, 3, {sceneResources,modelResources,drawResources});
foreach (model) {
vkCmdBindDescriptorSet(1, 2, {modelResources,drawResources});
foreach (draw) {
vkCmdBindDescriptorSet(2, 1, {drawResources});
vkDraw();
}
}
}
对应的shader伪代码:
layout(set=0,binding=0) uniform { ... } sceneData;
layout(set=1,binding=0) uniform { ... } modelData;
layout(set=2,binding=0) uniform { ... } drawData;
void main() { }

Vulkan绑定Descriptor流程图。
下图是另一个Vulkan的VkDescriptorSetLayoutBinding案例:

关于着色器绑定的使用,建议如下:
-
Root Signature最好存储在单个Descriptor Heap中,使用RingBuffer数据结构,使用静态的Sampler(最多2032个)。
-
不要超过Root Signature的尺寸。
- Root Signature内的CBV和常量应该最可能每个Draw Call都改变。
- 大部分在CB内的常量数据不应该是根常量。
-
只把小的、频繁使用的每次绘制都会改变的常量,直接放到Root Signature。
-
按照更新频率拆分Descriptor Table,最频繁更新的放在最前面(仅DirectX 12,Vulkan相反,Metal未知)。
-
Per-Draw,Per-Material,Per-Light,Per-Frame。
-
通过将最频繁改变的数据放置到根签名前面,来提供更新频率提示给驱动程序。

-
-
在启动时复制Root Signature到SGPR。
- 在编译器就确定好布局。
- 只需要为每个着色阶段拷贝。
- 如果占用太多SGPR,Root Signature会被拆分到Local Memory(下图),应避免这种情况!!

-
尽可能地使用静态表,可以提升性能。
-
保持RST(根签名表)尽可能地小。可以使用多个RST。
-
目标是每个Draw Call只改变一个Slot。
-
将资源可见性限制到最小的阶段集。
- 如果没必要,不要使用D3D12_SHADER_VISIBILITY_ALL。
- 尽量使用DENY_xxx_SHADER_ROOT_ACCESS。
-
要小心,RST没有边界检测。
-
在更改根签名之后,不要让资源绑定未定义。
-
AMD特有建议:
- 只有常量和CBV的逐Draw Call改变应该在RST内。
- 如果每次绘制改变超过一个CBV,那么最好将CBV放在Table中。
-
NV特有建议:
- 将所有常量和CBV放在RST中。
- RST中的常量和CBV确实会加速着色器。
- 根常量不需要创建CBV,意味着更少的CPU工作。
- 将所有常量和CBV放在RST中。
-
尽量缓存并重用DescriptorSet。

Fortnite缓存并复用DescriptorSet图例。
13.3.5 Heap, Buffer
| 概念 | UE | DirectX 12 | DirectX 11 | Vulkan | Metal | OpenGL |
|---|---|---|---|---|---|---|
| Heap | FRHIResource | ID3D12Resource, ID3D12Heap | - | Vk::MemoryHeap | MTLBuffer | - |
| Buffer | FRHIIndexBuffer, FRHIVertexBuffer | ID3D12Resource | ID3D11Buffer | vk::Buffer & vk::BufferView | MTLBuffer | GLuint |
Heap(堆)是包含GPU内存的对象,可以用来上传资源(如顶点缓冲、纹理)到GPU的专用内存。
Buffer(缓冲区)主要用于上传顶点索引、顶点属性、常量缓冲区等数据到GPU。
13.3.6 Fence, Barrier, Semaphore
| 概念 | UE | DirectX 12 | DirectX 11 | Vulkan | Metal | OpenGL |
|---|---|---|---|---|---|---|
| Fence | FRHIGPUFence | ID3D12Fence | ID3D11Fence | vk::Fence | MTLFence | glFenceSync |
| Barrier | FRDGBarrierBatch | D3D12_RESOURCE_BARRIER | - | vkCmdPipelineBarrier | MTLFence | glMemoryBarrier |
| Semaphore | - | HANDLE | HANDLE | vk::Semaphore | dispatch_semaphore_t | Varies by OS |
| Event | FEvent | - | - | Vk::Event | MTLEvent, MTLSharedEvent | Varies by OS |
Fence(栅栏)是用于同步CPU和GPU的对象。CPU或GPU都可以被指示在栅栏处等待,以便另一个可以赶上。可以用来管理资源分配和回收,使管理总体图形内存使用更容易。
Barrier(屏障)是更细粒度的同步形式,用在Command Buffer内。
Semaphore(信号量)是用于引入操作之间依赖关系的对象,例如在向设备队列提交命令缓冲区之前,在获取交换链中的下一个图像之前等待。Vulkan的独特之处在于,信号量是API的一部分,而DirectX和Metal将其委托给OS调用。
Event(事件)和Barrier类似,用来同步Command Buffer内的操作。对DirectX和OpenGL而言,需要依赖操作系统的API来实现Event。在UE内部,FEvent用来同步线程之间的信号。
Vulkan同步机制:semaphore(信号)用于同步Queue;Fence(栅栏)用于同步GPU和CPU;Event(事件)和Barrier(屏障)用于同步Command Buffer。
Vulkan semaphore在多个Queue之间的同步案例。
13.4 管线机制
13.4.1 Resource Management
对于现代的硬件架构而言,常见的内存模型如下所示:

现代计算机内存模型架构图。从上往下,容量越来越小,但带宽越来越大。
对于DirectX 11等传统API而言,资源内存需要依赖操作系统来管理生命周期,内存填充遍布所有时间,大部分直接变成了显存,会导致溢出,回传到系统内存。这种情况在之前没有受到太多人关注,而且似乎我们都习惯了驱动程序在背后偷偷