【kafka学习笔记】kafka的基本概念
在了解了背景知识后,我们来整体看一下kafka的基本概念,这里不做深入讲解,只是初步了解一下。
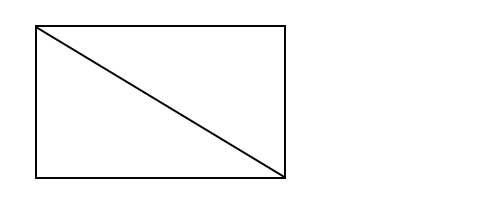
kafka的消息架构
注意这里不是设计的架构,只是为了方便理解,脑补的三层架构。从代码的实现来看,kafka其实就一层,不像MySQL分了服务层、引擎层之类的。
主题层
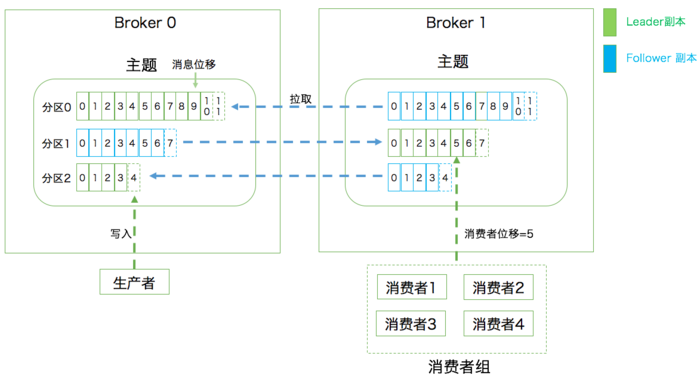
首先是主题层,Topic(主题),比如用户消息,命名为\'user_message\';支付消息,命名为\'pay_message\'。两者互不干扰,等于是两条道。
注意这里的Topic是逻辑概念,落到硬件上,应该叫partition(分区),为了提升吞吐量,kafka将一个主题分成了多个区,就像MongoDB 和 Elasticsearch 中的 Sharding、HBase 中的 Region,这是分布式的前提。
值得注意的是,kafka只保证单个partition上的顺序。谈到顺序,我们了解一下offest,它标记了消费者在这个partiotion上读到了哪一条。
那么我们想要顺序消费,也要提升消费速度,怎么办?
- 如果两个消费者同时消费同一个topic下的同一个partition,很显然,他们会重复消费。因为每个消费者的offest是独立保存的。
- 如果我们分成两个partition,假设topic的数据是123456, 采用随机分配的策略,partition1上的可能是135,2上面是246,消费者A读取1,B读取2,这样就不会重复消费了,但是如果A的速度很快,可能A都到5了,B的2还没读完。这就导致了乱序消费。
- 很简单,在上面的方案中,我们将随机分配改成哈希分配,从业务层将一个业务逻辑的消息发送到同一个partition上,比如用户ID。如果你的运气足够不好,可能会出现一个partition消息多,另一个少的情况。
好了,回顾下, topic,partition,offest。
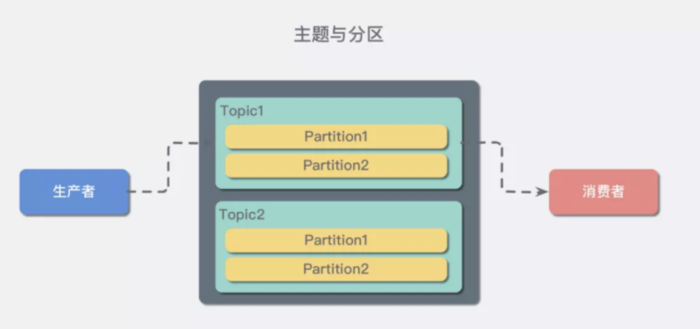
分区层
在实际应用中, 我们往往将partition分配在不同的磁盘上,利用多磁盘来增加读写效率。但是既然是分布式,必然需要多个机器,而一个机器,我们常常称为一个broker(节点)。
多节点不一定要再不同的机器上,只是我们之所以需要多节点就是为了防止意外宕机,如果都在同一台上,一死就全死了,毫无意义。
每个broker都有一套冗余数据,也叫做 repliaction(副本)。(天天网游里面下副本,今天终于知道副本是啥了吧。其实网游之所以有副本,就是为了防止玩家都涌入一个机器,在大家进入副本的时候,就切换到一个新的机器上了,和其他副本互不干扰。)
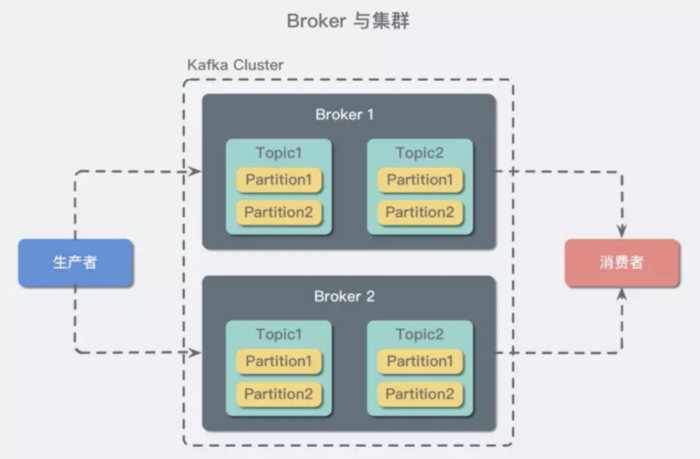
那么如果我们有三个节点,客户端怎么知道需要连接哪个呢?这就引入了两个概念,leader(领导者),follower(跟随者)。对了,还有个管家,叫zookeeper,它负责管理所有broker的IP地址,是否存活,然后怎么选取领导者,怎么换领导者。这中间的算法,我们后面再细细讲。
总之,zookeeper会选取leader,然后生产者和消费者只和leader交互。那么follower做啥?就是跟着跑,把leader的消息不断拉到本地,准备有一天等领导挂了自己成为新的领导。
(这里和MySQL不一样,MySQL的从库还负责给客户端读。)
好了,回顾下, broker,replication,leader,follower。
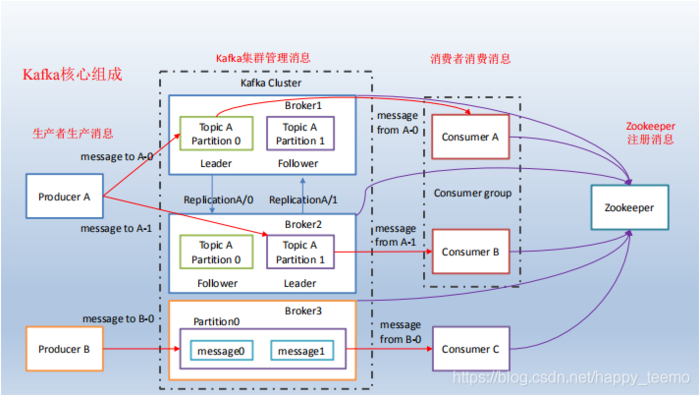
消息层
这一层主要是存储信息和消费者的offest。值得注意的是,消息是可以压缩的,上一篇也提到了,这样可以大大减少网络带宽。但是具体细节后面再说。
总结
kafka的陌生词汇还是挺多的,自己在脑海中多过两遍,总整体,到部分,有个基本概念就好,后面谈到的时候能更好地理解。
")