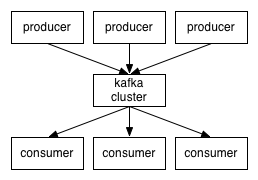
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。 kafka的诞生,是为了解决linkedin的数据管道问题,起初linkedin采用了ActiveMQ来进行数据交换,大约是在2010年前后,那时的ActiveMQ还远远无法满足linkedin对数据传递系统的要求,经常由于各种缺陷而导致消息阻塞或者服务无法正常访问,为了能够解决这个问题,linkedin决定研发自己的消息传递系统,当时linkedin的首席架构师jay kreps便开始组织团队进行消息传递系统的研发; 三种无需 Zookeeper 即可运行 Kafka 的简单方法从 2.8 版本开始,我们现在可以在没有 Zookeeper 的情况下运行 Ka... Kafka面试题总结1、Kafka 都有哪些特点? 高吞吐量、低延迟:kafka每秒可以处理几十万条... kafka2.x常用命令笔记(一)创建topic,查看topic列表、分区、副本详情,删除topic,测试topic发送与消费接触kafka开发已经两年多,也看过关于kafka的一些书,但一直没有怎么对它做...