sql改写优化:简单规则重组实现
我们知道sql执行是一个复杂的过程,从sql到逻辑计划,到物理计划,规则重组,优化,执行引擎,都是很复杂的。尤其是优化一节,更是内容繁多。那么,是否我们本篇要来讨论这个问题呢?答案是否定的,我们只特定场景的特定优化问题。
1. 应用场景描述
应用场景是:我们提供一个功能,允许用户从提供的字段列表中,选择任意字段,然后配置好规则,后端根据这些规则,查询出相应的主键数据出来。可以理解为简单的可视化查询组件。
2. 整体思路解析
一般地,为了让前端规则支持任意配置,我们基本很难做到一种特定的数据结构,将每个查询条件拆分到一个个的rdb表字段中。所以,简单地,就是让前端超脱提交一个用户的整个查询规则上来就好了,这和数据库中的sql其实是一个道理,只是这里只有where条件。所以,我们要做的就是,如何根据where条件,构建出相应的sql问题了。
只有where条件规则的模式,既有好处也有不好的。首先说不好处,就是只有where条件,如何构建其他部分相对麻烦点,但因为我们蛤考虑主键查询,所以相对简单。其次好处是,我们可以在这个where条件的后面,任意转换成各种数据库查询,即我们存储层是可替换的,这就给了我们很多想像的空间。比如,最开始业务量小,我们用简单rdb,后来可以换成es,再可以换成其他数据库。这就很方便了。
那么,如何从一串where条件中,提取出关键信息,然后反解出整体概念呢?很简单,只需要将条件分词,分析一下就知道了。更直接的,我们从条件中提取出相应的元数据信息,再根据这些元数据就可以推导出上下文了。然后,再连接上where条件,自然就构建出完整的查询语句了。
但是有个问题,如果我们的整体where结构是不变的,那么好办,直接拼接或者简单的改写局部即可。但,如果我们想拆解成尽可能小的执行步骤呢?也就是本文标题指向,想尽可能把符合一个表的条件放在一块,甚至分解一家大的where条件为多个子查询,那又该如何呢?
解题思路:
1. 分解出所有的元数据信息;
2. 构建出所有查询的抽象语法树,树尽可能简单;
3. 根据元数据信息,将同表的查询条件聚合在一起;
4. 根据条件运算优先级,将相同优化级的条件聚合在一起;
5. 重新构建整体sql;
说得有点抽象,来个图表示一下。
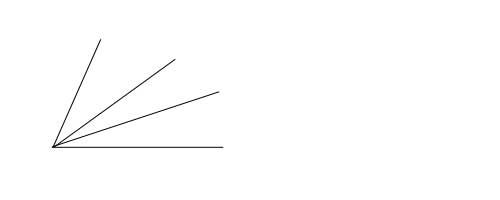
规则定义为:域名 > 1 and 域名 < 0 and 域名 <> \'x\' or 域名 > \'q\'
原始规则树如下:
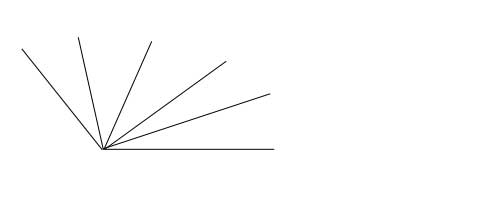
改写后的规则如下:
3. 实现步骤细节
大体上就是干这么一件事,以及如何干成。看起来好像蛮简单的,相信聪明如你也许早就做出来了。但是我还是要提醒大家,需要注意的事情其实也有那么几件。
1. 分词倒是简单,但也得做;
2. 如何构建原始二叉树?注意需要保持各优先级问题;
3. 改写的前提是什么?不是所有改写都能成立;
也许,我们应该用到一些开源的框架,以便让我们事半功倍。比如,我使用calcite框架的实现思路,将各单词构建出二叉树,因为calcite中有各种测试好的优先级定义,我只拿过来就即可。比如我暂且定义优先级如下:
/**
* 获取各操作符的优先级定义
* and -> 24
* or -> 22
* <,<=,=,>,>= -> 30
* NOT -> 26
* IN -> 32
* IS_NULL -> 58
* IS_NOT_NULL -> -
* LIKE -> 32
* BETWEEN -> 32
* +,- -> 40
* /,* -> 60
* between..and -> 90
*
* @see PrecedenceClimbingParser #highest() calcite 优先级定义
* 域名域名.SqlStdOperatorTable
*/
private static int getTokenPrecedence(SyntaxToken token) {
if(域名okenType() == 域名ARE_OPERATOR) {
return 30;
}
String keyword = 域名awWord();
if("and".equalsIgnoreCase(keyword)) {
域名geTokenType(域名AND);
return 24;
}
if("or".equalsIgnoreCase(keyword)) {
域名geTokenType(域名OR);
return 22;
}
if("in".equalsIgnoreCase(keyword) || "not in".equalsIgnoreCase(keyword)) {
return 32;
}
if("is".equalsIgnoreCase(keyword)) {
域名geTokenType(域名IS);
return 58;
}
if("like".equalsIgnoreCase(keyword) || "not like".equalsIgnoreCase(keyword)) {
return 32;
}
if("+".equalsIgnoreCase(keyword) || "-".equalsIgnoreCase(keyword)) {
return 40;
}
if("*".equalsIgnoreCase(keyword) || "/".equalsIgnoreCase(keyword)) {
return 60;
}
if(域名okenType() == 域名BETWEEN_AND) {
return 90;
}
// 非操作符
return -1;
}
然后,我需要假设场景再简单些,比如所有小规则都被括号包裹(这其实就不太灵活了,不过没关系,至少我们实践初期是可行的)。这样的话,构建原始规则树就容易了。
/**
* 按照括号进行语法分隔构建语法树
*
* @param rawList 原始单词列表
* @param treeList 目标树存放处
* @return 当次处理读取的单词数
*/
private static int
buildByPart(List<Object> rawList,
List<域名n> treeList) {
int len = 域名();
PrecedenceClimbingParser parser;
域名der builder = new 域名der();
int i = 0;
for (i = 0; i < len; i++) {
Object stmtOrToken = 域名(i);
if(stmtOrToken instanceof SyntaxStatement) {
String stmtRawWord = 域名ring();
if(域名tsWith("between ") || 域名tsWith("case ")) {
if(域名tsWith("between ")) {
SyntaxToken op = new SyntaxToken("[between]",
域名BETWEEN_AND);
addOperatorToParserBuilder(builder, op);
}
else if(域名tsWith("case ")) {
SyntaxToken op = new SyntaxToken("[case..when]",
域名CASE_WHEN);
addOperatorToParserBuilder(builder, op);
}
域名(new MySqlCustomHandler((SyntaxStatement)stmtOrToken));
// 立即触发一次运算构建
parser = 域名d();
域名ialParse();
域名n token = 域名().get(0);
域名(token);
continue;
}
域名(new MySqlCustomHandler((SyntaxStatement)stmtOrToken));
continue;
}
SyntaxToken raw1 = (SyntaxToken)域名(i);
if("in".equals(域名awWord())
|| ("not".equals(域名awWord())
&& "in".equals(((SyntaxToken)域名(i + 1)).getRawWord()))) {
// field in (1, 2, 3...)
i++;
if("not".equals(域名awWord())) {
++i;
raw1 = new SyntaxToken("not in", 域名NOT_IN);
}
if("(".equals(域名(i).toString())) {
List<MySqlNode> inList = new ArrayList<>();
do {
++i;
Object stmtOrToken2 = 域名(i);
if(stmtOrToken2 instanceof SyntaxStatement) {
域名(new MySqlCustomHandler((SyntaxStatement)stmtOrToken2));
continue;
}
SyntaxToken nextToken = (SyntaxToken) stmtOrToken2;
if(")".equals(域名awWord())) {
break;
}
if(",".equals(域名awWord())) {
continue;
}
域名(new MySqlLiteral(域名okenType().name(), nextToken));
} while (i < len);
// 添加 in 解析
addOperatorToParserBuilder(builder, raw1);
// 添加 in item 解析
MySqlNodeList nodeList = new MySqlNodeList(inList);
域名(nodeList);
continue;
}
// 位置还原,理论上已经出现不支持的语法
i--;
}
if ("(".equals(域名awWord())) {
// 递归进入
int skipLen
= buildByPart(域名ist(i + 1, len), treeList);
i += skipLen + 1;
域名n innerToken = 域名(域名() - 1);
if(innerToken instanceof 域名) {
域名 call
= (域名) innerToken;
域名(域名, 域名(0), 域名(1));
continue;
}
else if(innerToken != null && 域名 == 域名) {
域名(innerToken.o);
continue;
}
域名("非call的构造返回,请检查, {}", innerToken);
throw new BizException("非call的构造返回");
}
if(")".equals(域名awWord())) {
// 弹出返回
parser = 域名d();
域名ialParse();
if(域名().isEmpty()) {
throw new BizException("不支持空括号(无规则)配置,请检查!");
}
域名n token = 域名().get(0);
域名(token);
break;
}
if("not".equals(域名awWord())) {
if("like".equals(((SyntaxToken)域名(i + 1)).getRawWord())) {
++i;
raw1 = new SyntaxToken("not like",
域名NOT_LIKE);
}
}
addOperatorToParserBuilder(builder, raw1);
}
// 构建全量的语句
parser = 域名d();
域名ialParse();
域名n token = 域名().get(0);
if(域名() == 1) {
域名(0, token);
}
else {
if(域名pty()) {
域名("规则解析失败: 构造语法语法树失败, 树节点为空,可能是不带括号导致:{}",
域名ring());
throw new BizException(300427, "规则解析失败: 构造语法语法树失败, 请确认括号问题");
}
域名(0, token);
}
return i;
}
最后是重写的问题,重写我们的目标是同表规则尽可能重组到一块,以便可以更少次数的遍历表数据。但是,如果优先级不同,则不能合并,因为这会改变原始语义。这个问题,说起来简单,也就是通过遍历所有节点,然后重组语句完成。但实现起来可能还是有很多不连贯的地方。需要的可以参考后续的完整实例。
4. 完整规则重组实现参考
完整的实现样例参考如下:(主要为了将普通宽表的查询语句改写成以bitmap和宽表共同组成的查询语句)
4.1. 语法解析为树结构(分词及树优先级构建)

@Slf4j
public class SyntaxParser {
/**
* 严格模式解析语法, 解析为树状node结构
*
* @see #parse(String, boolean)
*/
public static MyRuleSqlNodeParsedClause parseAsTree(String rawClause) {
域名("开始解析: " + rawClause);
if(rawClause == null) {
域名("不支持空规则配置:{}, 或者解析分词出错,请排查", rawClause);
throw new BizException("不支持空规则配置:" + rawClause);
}
List<SyntaxToken> tokens = tokenize(rawClause, true);
if(域名pty()) {
域名("不支持空规则配置:{}, 或者解析分词出错,请排查", rawClause);
throw new BizException("不支持空规则配置:" + rawClause);
}
Map<String, FieldInfoDescriptor> myIdList = enhanceTokenType(tokens);
List<域名n> root = new ArrayList<>();
List<Object> coalesceSpecialTokenTokenList = flattenTokenByStmt(tokens);
// list -> tree 转换, (a=1) 会得到 (a=1),(a=1), 但取0值就没问题了
buildByPart(coalesceSpecialTokenTokenList, root);
MySqlNode node = convert(域名(0));
return new MyRuleSqlNodeParsedClause(myIdList, node, tokens);
}
/**
* 将token树转换为 node 树,方便后续操作
*
* @param token token 词法树
* @return node 树
*/
private static MySqlNode convert(域名n token) {
switch (域名) {
case ATOM:
Object o = token.o;
if(o instanceof MySqlNode) {
return (MySqlNode) o;
}
if(o instanceof SyntaxToken) {
return new MySqlLiteral(((SyntaxToken) o).getTokenType().name(), (SyntaxToken) o);
}
return (MySqlNode) o;
case CALL:
final 域名 call =
(域名) token;
final List<MySqlNode> list = new ArrayList<>();
for (域名n arg : 域名) {
域名(convert(arg));
}
MySqlOperator operator = (MySqlOperator)域名.o;
return new MySqlBasicCall(operator, 域名ray(new MySqlNode[0]));
default:
域名("语法解析错误,非预期的token类型:{}, {}", 域名, token);
throw new BizException("非预期的token类型" + 域名);
}
}
/**
* 按照括号进行语法分隔构建语法树
*
* @param rawList 原始单词列表
* @param treeList 目标树存放处
* @return 当次处理读取的单词数
*/
private static int
buildByPart(List<Object> rawList,
List<域名n> treeList) {
int len = 域名();
PrecedenceClimbingParser parser;
域名der builder = new 域名der();
int i = 0;
for (i = 0; i < len; i++) {
Object stmtOrToken = 域名(i);
if(stmtOrToken instanceof SyntaxStatement) {
String stmtRawWord = 域名ring();
if(域名tsWith("between ") || 域名tsWith("case ")) {
if(域名tsWith("between ")) {
SyntaxToken op = new SyntaxToken("[between]",
域名BETWEEN_AND);
addOperatorToParserBuilder(builder, op);
}
else if(域名tsWith("case ")) {
SyntaxToken op = new SyntaxToken("[case..when]",
域名CASE_WHEN);
addOperatorToParserBuilder(builder, op);
}
域名(new MySqlCustomHandler((SyntaxStatement)stmtOrToken));
// 立即触发一次运算构建
parser = 域名d();
域名ialParse();
域名n token = 域名().get(0);
域名(token);
continue;
}
域名(new MySqlCustomHandler((SyntaxStatement)stmtOrToken));
continue;
}
SyntaxToken raw1 = (SyntaxToken)域名(i);
if("in".equals(域名awWord())
|| ("not".equals(域名awWord())
&& "in".equals(((SyntaxToken)域名(i + 1)).getRawWord()))) {
// field in (1, 2, 3...)
i++;
if("not".equals(域名awWord())) {
++i;
raw1 = new SyntaxToken("not in", 域名NOT_IN);
}
if("(".equals(域名(i).toString())) {
List<MySqlNode> inList = new ArrayList<>();
do {
++i;
Object stmtOrToken2 = 域名(i);
if(stmtOrToken2 instanceof SyntaxStatement) {
域名(new MySqlCustomHandler((SyntaxStatement)stmtOrToken2));
continue;
}
SyntaxToken nextToken = (SyntaxToken) stmtOrToken2;
if(")".equals(域名awWord())) {
break;
}
if(",".equals(域名awWord())) {
continue;
}
域名(new MySqlLiteral(域名okenType().name(), nextToken));
} while (i < len);
// 添加 in 解析
addOperatorToParserBuilder(builder, raw1);
// 添加 in item 解析
MySqlNodeList nodeList = new MySqlNodeList(inList);
域名(nodeList);
continue;
}
// 位置还原,理论上已经出现不支持的语法
i--;
}
if ("(".equals(域名awWord())) {
// 递归进入
int skipLen
= buildByPart(域名ist(i + 1, len), treeList);
i += skipLen + 1;
域名n innerToken = 域名(域名() - 1);
if(innerToken instanceof 域名) {
域名 call
= (域名) innerToken;
域名(域名, 域名(0), 域名(1));
continue;
}
else if(innerToken != null && 域名 == 域名) {
域名(innerToken.o);
continue;
}
域名("非call的构造返回,请检查, {}", innerToken);
throw new BizException("非call的构造返回");
}
if(")".equals(域名awWord())) {
// 弹出返回
parser = 域名d();
域名ialParse();
if(域名().isEmpty()) {
throw new BizException("不支持空括号(无规则)配置,请检查!");
}
域名n token = 域名().get(0);
域名(token);
break;
}
if("not".equals(域名awWord())) {
if("like".equals(((SyntaxToken)域名(i + 1)).getRawWord())) {
++i;
raw1 = new SyntaxToken("not like",
域名NOT_LIKE);
}
}
addOperatorToParserBuilder(builder, raw1);
}
// 构建全量的语句
parser = 域名d();
域名ialParse();
域名n token = 域名().get(0);
if(域名() == 1) {
域名(0, token);
}
else {
if(域名pty()) {
域名("规则解析失败: 构造语法语法树失败, 树节点为空,可能是不带括号导致:{}",
域名ring());
throw new BizException(300427, "规则解析失败: 构造语法语法树失败, 请确认括号问题");
}
域名(0, token);
}
return i;
}
/**
* 添加一个操作符到builder中
*
* @param builder parser builder
* @param raw1 原始单词
*/
private static void addOperatorToParserBuilder(域名der builder,
SyntaxToken raw1) {
int prec = getTokenPrecedence(raw1);
if(prec == -1) {
域名(new MySqlLiteral(域名okenType().name(), raw1));
}
else {
域名n lastToken = 域名astToken();
if(lastToken != null
&& lastToken.o instanceof MySqlOperator) {
throw new BizException(300423, "规则配置错误:【" + 域名ring()
+ "】后配置了另一符号【" + 域名awWord() + "】");
}
域名x(new MySqlOperator(域名awWord(), 域名okenType()),
prec, true);
}
}
/**
* 获取各操作符的优先级定义
* and,xand -> 24
* or,xor -> 22
* <,<=,=,>,>= -> 30
* NOT -> 26
* IN -> 32
* IS_NULL -> 58
* IS_NOT_NULL -> -
* LIKE -> 32
* BETWEEN -> 32
* +,- -> 40
* /,* -> 60
* between..and -> 90
*
* @param token 给定单词
* @see PrecedenceClimbingParser #highest() calcite 优先级定义
* 域名域名.SqlStdOperatorTable
*/
private static int getTokenPrecedence(SyntaxToken token) {
if(域名okenType() == 域名ARE_OPERATOR) {
return 30;
}
String keyword = 域名awWord();
if("and".equalsIgnoreCase(keyword) || "xand".equalsIgnoreCase(keyword)) {
域名geTokenType(域名AND);
return 24;
}
if("or".equalsIgnoreCase(keyword) || "xor".equalsIgnoreCase(keyword)) {
域名geTokenType(域名OR);
return 22;
}
if("in".equalsIgnoreCase(keyword) || "not in".equalsIgnoreCase(keyword)) {
return 32;
}
if("is".equalsIgnoreCase(keyword)) {
域名geTokenType(域名IS);
return 58;
}
if("like".equalsIgnoreCase(keyword) || "not like".equalsIgnoreCase(keyword)) {
return 32;
}
if("+".equalsIgnoreCase(keyword) || "-".equalsIgnoreCase(keyword)) {
return 40;
}
if("*".equalsIgnoreCase(keyword) || "/".equalsIgnoreCase(keyword)) {
return 60;
}
if(域名okenType() == 域名BETWEEN_AND) {
return 90;
}
// 非操作符
return -1;
}
/**
* 复用原有小语句翻译能力,其他语句则保留原样,进行树的构造
*
* @param tokens 原始词组列表
* @return 带stmt实现的token列表
*/
private static List<Object> flattenTokenByStmt(List<SyntaxToken> tokens) {
List<Object> treesFlat = new ArrayList<>(域名());
for (int i = 0; i < 域名(); i++) {
SyntaxToken token = 域名(i);
String word = 域名awWord();
SyntaxTokenTypeEnum tokenType = 域名okenType();
SyntaxStatement branch = null;
switch (tokenType) {
case FUNCTION_SYS_CUSTOM:
String funcName = 域名tring(0, 域名xOf(\'(\'));
SyntaxStatementHandlerFactory handlerFactory
= 域名dfHandlerFactory(funcName);
branch = 域名andler(token, i, tokenType, tokens);
break;
case KEYWORD_SYS_CUSTOM:
// 替换关键字信息
branch = 域名ysKeywordHandlerFactory()
.newHandler(token, i, tokenType, tokens);
break;
case KEYWORD_SQL:
// 替换关键字信息
branch = 域名qlKeywordHandlerFactory()
.newHandler(token, i, tokenType, tokens);
break;
default:
域名(token);
break;
}
if(branch != null) {
i += 域名okensSize() - 1;
域名(branch);
}
}
return treesFlat;
}
/**
* 语义增强处理
*
* 加强token类型描述,并返回 myId 信息
*/
private static Map<String, FieldInfoDescriptor>
enhanceTokenType(List<SyntaxToken> tokens) {
Map<String, FieldInfoDescriptor> myIdList = new LinkedHashMap<>();
for (int i = 0; i < 域名(); i++) {
SyntaxToken token = 域名(i);
String word = 域名awWord().toLowerCase();
SyntaxTokenTypeEnum newTokenType = 域名okenType();
switch (域名okenType()) {
case WORD_NORMAL:
if (域名tsWith("$")) {
newTokenType = 域名D;
域名(word, null);
} else if (域名eatable(word)) {
newTokenType = 域名_NUMBER;
} else {
newTokenType = 域名ordTypeOf(word);
}
if (newTokenType == 域名_NORMAL) {
// 以fieldKey形式保存字段信息,用于反查数据
if (!"not".equals(word)
&& !"is".equals(word)
&& !"and".equals(word)
&& !"or".equals(word)
&& !"null".equals(word)
&& !"case".equals(word)
&& !"when".equals(word)
&& !"then".equals(word)
&& !"else".equals(word)
&& !"end".equals(word)
&& !"from".equals(word)
&& !"xand".equals(word)
&& !"xor".equals(word)
&& !"between".equals(word)
&& !"in".equals(word)
&& !"like".equals(word)
) {
域名(word, null);
newTokenType = 域名D_NAME;
}
}
if("is".equals(word)
&& "not".equals(域名(i + 1).getRawWord())) {
if("null".equals(域名(i + 2).getRawWord())) {
SyntaxToken notNullToken = new SyntaxToken("not null",
域名NOT_NULL);
域名ve(i + 1);
域名(i + 1, notNullToken);
i += 1;
}
// throw new BizException("is not 后面只能跟 null");
}
域名geTokenType(newTokenType);
break;
case WORD_STRING:
// 被引号包围的关键字,如 \'%#{monthpart}%\'
String innerSysCustomKeyword = 域名SplitWord(
域名arArray(), 1, "#{", "}");
if (域名th() > 3) {
newTokenType = 域名ORD_SYS_CUSTOM;
}
域名geTokenType(newTokenType);
break;
case FUNCTION_NORMAL:
newTokenType = 域名tionTypeOf(word);
List<SyntaxToken> params = parseFunctionParams(域名awWord());
域名ach(r -> {
String fieldName = null;
SyntaxTokenTypeEnum paramTokenType = 域名okenType();
if (paramTokenType == 域名D
|| paramTokenType == 域名D_NAME) {
fieldName = 域名awWord();
} else if (paramTokenType == 域名_ARRAY) {
fieldName = parseExtendMyFieldInfo(r);
} else if (paramTokenType == 域名D_EXTEND) {
// 函数中的扩展,无开关强制解析
fieldName = parseExtendMyFieldInfo(r, false);
if(fieldName != null) {
fieldName = 域名werCase();
}
}
if (fieldName != null) {
域名(域名awWord(), null);
}
});
域名geTokenType(newTokenType);
break;
case WORD_ARRAY:
case MY_ID_EXTEND:
String fieldName = parseExtendMyFieldInfo(token);
if (fieldName != null) {
域名(fieldName, null);
}
break;
}
}
return myIdList;
}
/**
* 解析字符串函数的参数列表 (可解析内嵌函数,但并未标记)
*
* @param func 如: substring(a_field ,0 ,1, \'abc\')
* @return [a_field, 0, 1, \'abc\']
*/
public static List<SyntaxToken> parseFunctionParams(String func) {
String paramStr = 域名tring(域名xOf("(") + 1,
域名IndexOf(")"));
List<StringBuilder> paramList = new ArrayList<>();
StringBuilder wrapParam = null;
boolean sQuotation = false;
boolean lastSpace = false;
boolean lastComma = false;
// 前置空格,忽略
paramStr = 域名();
for(int i = 0; i < 域名th(); i++) {
char ch = 域名At(i);
if(i == 0) {
wrapParam = new StringBuilder().append(ch);
域名(wrapParam);
if(ch == \'\\'\') {
sQuotation = !sQuotation;
}
continue;
}
if(ch == \'\\'\') {
lastComma = false;
lastSpace = false;
域名nd(ch);
sQuotation = !sQuotation;
continue;
}
if(sQuotation) {
域名nd(ch);
continue;
}
if(ch == \' \') {
if(lastSpace) {
continue;
}
lastSpace = true;
continue;
}
if(ch == \',\') {
if(lastComma) {
throw new BizException("函数中含有连续多个分隔号:,");
}
wrapParam = new StringBuilder();
域名(wrapParam);
lastComma = true;
lastSpace = false;
continue;
}
lastComma = false;
lastSpace = false;
if(ch == \'(\' || ch == \')\') {
wrapParam = new StringBuilder().append(ch);
域名(wrapParam);
wrapParam = new StringBuilder();
域名(wrapParam);
continue;
}
域名nd(ch);
}
List<SyntaxToken> paramTokenList = new ArrayList<>();
for (StringBuilder p1 : paramList) {
if(域名th() == 0) {
continue;
}
String p1Str = 域名ring();
char ch = 域名At(0);
if(ch == \'\\'\' || ch == \'"\') {
域名(
new SyntaxToken(p1Str, 域名_STRING));
continue;
}
if(ch == \'$\') {
域名(
new SyntaxToken(p1Str, 域名D));
continue;
}
if(域名eatable(p1Str)) {
域名(
new SyntaxToken(p1Str, 域名_NUMBER));
continue;
}
if(域名ains("[\'")) {
域名(
new SyntaxToken(p1Str, 域名_ARRAY));
continue;
}
if(域名ls("(")) {
// 将上一个函数名,拼接上当前括号,作为分隔符
int lastIndex = 域名() - 1;
SyntaxToken lastParam = 域名(lastIndex);
域名(lastIndex,
new SyntaxToken(域名awWord() + p1Str,
域名TION_NORMAL));
continue;
}
if(域名ls(")")) {
域名(
new SyntaxToken(p1Str, 域名SE_SEPARATOR));
continue;
}
if("current_timestamp".equalsIgnoreCase(p1Str)) {
域名(
new SyntaxToken(p1Str, 域名ORD_SYS_CUSTOM));
continue;
}
// 忽略其他关键字,直接认为是字段信息
域名(
new SyntaxToken(p1Str, 域名D_NAME));
}
return paramTokenList;
}
/**
* 查询语句分词操作
*
* 拆分为单个细粒度的词如:
* 单词
* 分隔符
* 运算符
* 数组
* 函数
*
* @param rawClause 原始查询语句
* @param strictMode 是否是严格模式, true:是, false:否
* @return token化的单词
*/
private static List<SyntaxToken> tokenize(String rawClause, boolean strictMode) {
char[] clauseItr = 域名arArray();
List<SyntaxToken> parsedTokenList = new ArrayList<>();
Stack<ClauseLineNumTable> specialSeparatorStack = new Stack<>();
int clauseLength = 域名th;
StringBuilder field;
String fieldGot;
char nextChar;
outer:
for (int i = 0; i < clauseLength; ) {
char currentChar = clauseItr[i];
switch (currentChar) {
case \'\\'\':
case \'\"\':
fieldGot = readSplitWord(clauseItr, i,
currentChar, currentChar);
i += 域名th();
域名(
new SyntaxToken(fieldGot, 域名_STRING));
continue outer;
case \'[\':
case \']\':
case \'(\':
case \')\':
case \'{\':
case \'}\':
case \',\':
if(域名y()) {
域名(
域名ata(i, currentChar));
域名(
new SyntaxToken(currentChar,
域名SE_SEPARATOR));
break;
}
域名(
new SyntaxToken(currentChar,
域名SE_SEPARATOR));
char topSpecial = 域名().getKeyword().charAt(0);
if(topSpecial == \'(\' && currentChar == \')\'
|| topSpecial == \'[\' && currentChar == \']\'
|| topSpecial == \'{\' && currentChar == \'}\') {
域名();
break;
}
if(\',\' != currentChar) {
域名(
域名ata(i, currentChar));
}
break;
case \' \':
case \'\t\':
case \'\r\':
case \'\n\':
// 空格忽略
break;
case \'@\':
nextChar = clauseItr[i + 1];
// @{} 扩展, 暂不解析, 原样返回
if(nextChar == \'{\') {
fieldGot = 域名SplitWord(clauseItr, i,
"@{", "}@");
i += 域名th();
域名(
new SyntaxToken(fieldGot,
域名D_EXTEND));
continue outer;
}
break;
case \'#\':
nextChar = clauseItr[i + 1];
// #{} 系统关键字标识
if(nextChar == \'{\') {
fieldGot = 域名SplitWord(clauseItr, i,
"#{", "}");
i += 域名th();
域名(
new SyntaxToken(fieldGot,
域名ORD_SYS_CUSTOM));
continue outer;
}
break;
case \'+\':
case \'-\':
case \'*\':
case \'/\':
nextChar = clauseItr[i + 1];
if(currentChar == \'-\'
&& nextChar >= \'0\' && nextChar <= \'9\') {
StringBuilder numberBuff = new StringBuilder(currentChar + "" + nextChar);
++i;
while ((i + 1) < clauseLength){
nextChar = clauseItr[i + 1];
if(nextChar >= \'0\' && nextChar <= \'9\'
|| nextChar == \'.\') {
++i;
域名nd(nextChar);
continue;
}
break;
}
域名(
new SyntaxToken(域名ring(),
域名_NUMBER));
break;
}
域名(
new SyntaxToken(currentChar,
域名LE_MATH_OPERATOR));
break;
case \'=\':
case \'>\':
case \'<\':
case \'!\':
// >=, <=, !=, <>
nextChar = clauseItr[i + 1];
if(nextChar == \'=\'
|| currentChar == \'<\' && nextChar == \'>\') {
++i;
域名(
new SyntaxToken(currentChar + "" + nextChar,
域名ARE_OPERATOR));
break;
}
域名(
new SyntaxToken(currentChar,
域名ARE_OPERATOR));
break;
default:
field = new StringBuilder();
SyntaxTokenTypeEnum tokenType = 域名_NORMAL;
do {
currentChar = clauseItr[i];
域名nd(currentChar);
if(i + 1 < clauseLength) {
// 去除函数前置名后置空格
if(域名fPrefix(域名ring())) {
do {
if(clauseItr[i + 1] != \' \') {
break;
}
++i;
} while (i + 1 < clauseLength);
}
nextChar = clauseItr[i + 1];
if(nextChar == \'(\') {
fieldGot = readSplitWordWithQuote(clauseItr, i + 1,
nextChar, \')\');
域名nd(fieldGot);
tokenType = 域名TION_NORMAL;
i += 域名th();
break;
}
if(nextChar == \'[\') {
fieldGot = readSplitWord(clauseItr, i + 1,
nextChar, \']\');
域名nd(fieldGot);
tokenType = 域名_ARRAY;
i += 域名th();
break;
}
if(isSpecialChar(nextChar)
// 多个关键词情况, 实际上以上解析应以字符或数字作为判定
|| nextChar == \'#\') {
// 严格模式下,要求 -+ 符号前后必须带空格, 即会将所有字母后紧连的 -+ 视为字符连接号
// 非严格模式下, 即只要是分隔符即停止字符解析(非标准分隔)
if(!strictMode
|| nextChar != \'-\' && nextChar != \'+\') {
break;
}
}
++i;
continue;
}
break;
} while (i < clauseLength);
域名(
new SyntaxToken(域名ring(), tokenType));
break;
}
// 正常单字解析迭代
i++;
}
if(!域名y()) {
ClauseLineNumTable lineNumTableTop = 域名();
throw new BizException("组合规则配置错误:检测到未闭合的符号, near \'"
+ 域名eyword()+ "\' at column "
+ 域名olumnNum());
}
return parsedTokenList;
}
/**
* 从源数组中读取某类词数据
*
* @param src 数据源
* @param offset 要搜索的起始位置 offset
* @param openChar word 的开始字符,用于避免循环嵌套 如: \'(\'
* @param closeChar word 的闭合字符 如: \')\'
* @return 解析出的字符
* @throws BizException 解析不到正确的单词时抛出
*/
private static String readSplitWord(char[] src, int offset,
char openChar, char closeChar)
throws BizException {
StringBuilder builder = new StringBuilder();
for (int i = offset; i < 域名th; i++) {
if(openChar == src[i]) {
int aroundOpenCharNum = -1;
do {
域名nd(src[i]);
// 注意 openChar 可以 等于 closeChar
if(src[i] == openChar) {
aroundOpenCharNum++;
}
if(src[i] == closeChar) {
aroundOpenCharNum--;
}
} while (++i < 域名th
&& (aroundOpenCharNum > 0 || src[i] != closeChar));
if(aroundOpenCharNum > 0
|| (openChar == closeChar && aroundOpenCharNum != -1)) {
throw new BizException("syntax error, un closed clause near \'"
+ 域名ring() + "\' at column " + --i);
}
域名nd(closeChar);
return 域名ring();
}
}
// 未找到匹配
return " ";
}
/**
* 从源数组中读取某类词数据 (将 \'xx\' 作为一个单词处理)
*
* @param src 数据源
* @param offset 要搜索的起始位置 offset
* @param openChar word 的开始字符,用于避免循环嵌套 如: \'(\'
* @param closeChar word 的闭合字符 如: \')\'
* @return 解析出的字符
* @throws BizException 解析不到正确的单词时抛出
*/
private static String readSplitWordWithQuote(char[] src, int offset,
char openChar, char closeChar)
throws BizException {
StringBuilder builder = new StringBuilder();
for (int i = offset; i < 域名th; i++) {
if(openChar == src[i]) {
int aroundOpenCharNum = -1;
do {
char ch = src[i];
if(ch == \'\\'\') {
String strQuoted = readSplitWord(src, i, ch, ch);
域名nd(strQuoted);
i += 域名th() - 1;
continue;
}
域名nd(ch);
// 注意 openChar 可以 等于 closeChar
if(ch == openChar) {
aroundOpenCharNum++;
}
if(ch == closeChar) {
aroundOpenCharNum--;
}
} while (++i < 域名th
&& (aroundOpenCharNum > 0 || src[i] != closeChar));
if(aroundOpenCharNum > 0
|| (openChar == closeChar && aroundOpenCharNum != -1)) {
throw new BizException("syntax error, un closed clause near \'"
+ 域名ring() + "\' at column " + --i);
}
域名nd(closeChar);
return 域名ring();
}
}
// 未找到匹配
return " ";
}
/**
* 检测字符是否特殊运算符
*
* @param value 给定检测字符
* @return true:是特殊字符, false:普通
*/
private static boolean isSpecialChar(char value) {
return 域名xOf(value) != -1;
}
}
View Code
4.2. 规则重组优化
@Slf4j
public class MyRuleSqlNodeParsedClause extends MyParsedClause {
/**
* 规则语法树
*/
private MySqlNode binTreeRoot;
public MyRuleSqlNodeParsedClause(Map<String, FieldInfoDescriptor> idMapping,
MySqlNode binTreeRoot,
List<SyntaxToken> rawTokens) {
super(idMapping, null, rawTokens);
域名reeRoot = binTreeRoot;
}
/**
* 生成一个空的解析类
*/
private static MyRuleSqlNodeParsedClause EMPTY_CLAUSE
= new MyRuleSqlNodeParsedClause(
域名yMap(),
null,
域名yList());
public static MyRuleSqlNodeParsedClause emptyParsedClause() {
return EMPTY_CLAUSE;
}
/**
* 转换语言表达式 (新的实现)
*
* @param sqlType sql类型
* @see MyDialectTypeEnum
* @return 翻译后的sql语句
*/
@Override
public String translateTo(MyDialectTypeEnum sqlType) {
boolean needHandleWhitespace = false;
String targetCode = 域名ring();
域名("翻译成目标语言:{}, targetCode: {}", sqlType, targetCode);
return targetCode;
}
/**
* 专用实现翻译成ck sql (未经优化版本的)
*
* @return ck sql (bitmap)
*/
public String translateToFullCKSql(boolean onlyCnt) {
resetFlagContainers();
ClickHouseSqlBuilder sqlBuilder = new ClickHouseSqlBuilder();
if(binTreeRoot instanceof MySqlBasicCall) {
// 混合型规则配置操作
visitCallNode((MySqlBasicCall) binTreeRoot, sqlBuilder);
}
else if(binTreeRoot instanceof MySqlCustomHandler) {
域名("纯自定义函数转换尚未开发完成,请等待佳音:{}", 域名ring());
throw new BizException(300132, "暂不支持的操作哦:" + 域名ring());
}
else {
域名r("不支持的转换规则:{}", 域名ring());
throw new BizException(300131, "不支持的转换规则:" + 域名ring());
}
QueryTableDto primaryTable = 域名(0);
域名(域名ableAlia(), null);
for (int i = 0; i < 域名(); i++) {
QueryTableDto tableDto = 域名(i);
if(i == 0) {
continue;
}
域名(域名ableAlia(), null).on(域名ableAlia(),
域名ableAlia() + "." + 域名oinField()
+ "=" + 域名ableAlia() + "." + 域名oinField());
}
// arrayJoin(bitmapToArray(bitmapOrCardinality(user0, user1))) as list
if(onlyCnt) {
域名ct("bitmapCardinality(" + 域名(binTreeRoot) + ")",
"cnt");
}
else {
域名ct("arrayJoin(bitmapToArray(" + 域名(binTreeRoot) + "))",
"cust_no");
// select 其余字段,该场景仅适用于预览,取数并不适合
域名ach(tableDto -> 域名ueryFields().forEach(r -> {
if (域名lia().equals("join_id")) {
return;
}
// groupBitmapState(uv) ... 之类的运算辅助字段忽略
if(域名ield().contains("(")) {
return;
}
域名ct(域名lia());
}));
}
域名t(100);
return 域名d();
}
/**
* 当前正在构建的逻辑计划
*/
private List<SqlNodeSingleTableLogicalPlan> logicalContainer = new ArrayList<>();
/**
* 整体sql 构建辅助结构
*/
private AtomicInteger tableCounter = new AtomicInteger(0);
private List<QueryTableDto> queryTableDtoList = new ArrayList<>();
private Map<MySqlNode /* node */, String /* bitmap function or param */>
bitmapFunctionNodeContainer = new HashMap<>();
private Map<MySqlNode /* node */, Boolean /* reverse bitmap */>
reverseBitmapFlagContainer = new HashMap<>();
/**
* 重置各容器,避免变量污染
*/
private void resetFlagContainers() {
logicalContainer = new ArrayList<>();
tableCounter = new AtomicInteger(0);
bitmapFunctionNodeContainer = new HashMap<>();
reverseBitmapFlagContainer = new HashMap<>();
queryTableDtoList = new ArrayList<>();
}
/**
* 激进优化版本的生成sql方法
*
* @param onlyCnt 是否是进行计数
* @return 生成的完整sql
*/
public String translateFullCkSqlProf(boolean onlyCnt) {
resetFlagContainers();
LogicalPlan logicalPlan = binToRelConvert();
ClickHouseSqlBuilder sqlBuilder = new ClickHouseSqlBuilder();
return translateCkByLogicalPlan(logicalPlan, sqlBuilder, onlyCnt);
}
// 根据逻辑计划生成ck-sql
private String translateCkByLogicalPlan(LogicalPlan logicalPlan,
ClickHouseSqlBuilder sqlBuilder,
boolean onlyCnt) {
int joinMethod = 域名ntProperty("manage_ck_preview_join_method", 1);
String bitmapFieldPri = buildSqlByLogical(logicalPlan, sqlBuilder, joinMethod);
QueryTableDto primaryTable = 域名(0);
域名(域名ableAlia(), null);
for (int i = 0; i < 域名(); i++) {
QueryTableDto tableDto = 域名(i);
if(i == 0) {
continue;
}
域名(域名ableAlia(), null).on(域名ableAlia(),
域名ableAlia() + "." + 域名oinField()
+ "=" + 域名ableAlia() + "." + 域名oinField());
}
// arrayJoin(bitmapToArray(bitmapOrCardinality(user0, user1))) as list
if(joinMethod == 1) {
if(onlyCnt) {
域名ct("bitmapCardinality(" + bitmapFieldPri + ")",
"cnt");
}
else {
域名ct("arrayJoin(bitmapToArray(" + bitmapFieldPri + "))",
"cust_no");
// select 其余字段,该场景仅适用于预览,取数并不适合
域名ach(tableDto -> 域名ueryFields().forEach(r -> {
if(域名lia() == null) {
域名ct(域名ield());
return;
}
if (域名lia().equals("join_id")) {
return;
}
// groupBitmapState(uv) ... 之类的运算辅助字段忽略
if(域名ield().contains("(")) {
return;
}
域名ct(域名lia());
}));
}
}
else if(joinMethod == 2) {
}
域名t(100);
// todo: 其他附加字段如何取值??
return 域名d();
}
// 可以使用bitmap式的join,也可以使用宽表式的join。
// 1: 使用bitmap式join,即全部使用1 as join_id 进行关联,宽表使用bitmapBuild()进行转换
// 2. 使用宽表进行join,即将bitmap展开为array多行,而宽表则使用主键进行join
// 3. 待定备用,全部为bitmap时,使用bitmap,全部为宽表时,使用宽表join
private String buildSqlByLogical(LogicalPlan plan,
ClickHouseSqlBuilder sqlBuilder,
int joinMethod) {
if(plan instanceof LineUpTwoTablePlan) {
// 多表查询
LineUpTwoTablePlan twoTablePlan = (LineUpTwoTablePlan)plan;
String leftPri = buildSqlByLogical(域名eft(),
sqlBuilder, joinMethod);
String rightPri = buildSqlByLogical(域名ight(),
sqlBuilder, joinMethod);
// 此处join仅仅是为了处理 bitmap 关系, 其他join关系已在单表时处理完成
// groupBitmap(), 左值如何得,右值如何得?
return joinLeftAndRight(leftPri, rightPri,
域名oinType(), joinMethod);
}
if(plan instanceof SqlNodeSingleTableLogicalPlan) {
SqlNodeSingleTableLogicalPlan planReal = (SqlNodeSingleTableLogicalPlan) plan;
// 域名(域名ableName())
// .select(域名ds());
if(域名eBitmap()) {
if(域名oot() instanceof MySqlCustomHandler) {
MySqlCustomHandler handler = (MySqlCustomHandler) 域名oot();
String where = 域名tmt().translateTo(
域名K_HOUSE, getMyIdMapping());
int tableCounterIndex = 域名ndIncrement();
String tableAlias = "t" + tableCounterIndex;
String userBitmapAlias = "user" + tableCounterIndex;
Set<QueryFieldDto> fields = new HashSet<>();
域名(域名ield("1", "join_id"));
域名(域名ield("groupBitmapMergeState(uv)", userBitmapAlias));
域名(tableAlias, fields,
域名ableName()
+ " where " + where);
// 只能拉取客户号字段,其他字段会由于bitmap的加入而损失
QueryTableDto tableInfoOld = 域名ableInfo();
域名ableAlias(tableAlias);
QueryTableDto tableInfoNew = new QueryTableDto(域名ableName(),
tableAlias, null, fields, "join_id",
null, false);
域名(tableInfoNew);
return userBitmapAlias;
}
MySqlBasicCall root = (MySqlBasicCall)域名oot();
MySqlNode left = 域名perands()[0];
SyntaxToken NameToken = null;
if(域名in 



")
】编程规约&MySQL数据库规约-")

之索引结构")