图挖掘的算法演进与硬件加速

由于来自不规则图结构的过度随机访问和幂律度分布的显着负载不平衡,图长期以来一直被视为系统和架构社区中具有挑战性的数据类型。超越传统的图分析,如 PageRank 和单源最短路径,图挖掘(这实际上是对术语的轻微滥用,我们将在本文末尾重新讨论)是一个新出现的问题,它将同构的所有子图定位到给定的感兴趣模式。这些子图称为输入图中模式的嵌入。图挖掘的关键能力是发现丰富的结构信息,例如派系、主题和其他特定于应用程序的模式,这为许多重要应用程序提供了重要的见解。例如,生物/化学信息学发现蛋白质、基因和化合物中的 3D 基序;社会科学通过社交网络连接识别人群中的密集派系;垃圾邮件/欺诈检测与特定的异常通信和财务关系模式相匹配。
然而,尽管图挖掘具有强大的功能,但从根本上说,它比传统的图算法更需要计算和内存密集型,导致可扩展性较差。由于组合爆炸,可能的模式集和每个模式的嵌入数量随着输入图的大小呈超线性甚至指数增长。即使是具有数千条边的中等大图也可能生成数百万个中间嵌入。这些困难一直在推动最近图挖掘的算法演变和硬件加速。
算法进化改变硬件加速
关于图挖掘的一件特别有趣的事情是快速发展的算法如何引导和转移相应硬件支持的重点。与具有相对成熟算法和稳定内核集的其他领域(例如,深度学习)不同,对于图挖掘,算法是否已经收敛到一个最优化的主流仍然不清楚。当前的计算复杂度和内存占用仍然如此之高,以至于新的算法突破可能会带来几个数量级的加速,与硬件加速的好处相当甚至超过。这导致了一个不寻常的场景:更优化的算法范式在之前的最先进技术之后不久不断出现,使得刚刚提出的基于旧模型的硬件设计甚至比新的软件执行速度慢!
事实上,从2015 年的Arabesque开始,许多早期的通用图挖掘框架都采用了“ think-like-an-embedding ”的编程模型,其灵感来自经典的“think-like-a-vertex”模型。这种范式在每次迭代时逐渐将更多边扩展到中间候选子图,直到生成如下图所示的所有嵌入,许多分布式框架都遵循了进一步优化。例如,G-Miner使用基于任务的异步执行。Fractal提出了一种用于子图枚举的深度优先 (DFS) 策略,而不是 Arabesque 中的广度优先 (BFS),以减少内存占用。和aDFS进一步使用了结合 DFS 和 BFS 优点的几乎 DFS 探索。GRAMER是第一个用于图形挖掘的硬件加速器,它基于这种编程范式,并且在上述软件系统上表现出显着的加速。
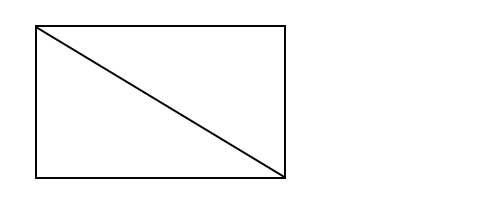
匹配输入图形(左上)中的尾部三角形模式(左下)。对于“think-like-an-embedding”,(部分)嵌入是主要对象。每次迭代都会将一个顶点扩展到部分嵌入,从而形成树状探索,其中多个分支代表新添加顶点的不同选择(右)。例如,在最左边的路径中,u 0映射到 2,u 1映射到 1,u 2映射到 3,而 u 3映射到 4。可以按深度优先或广度优先的顺序探索树。
在另一方面,一些系统(例如,BiGJoin和RStream在2018和Mhedhbi和Salihoglu在2019)建模的图挖掘问题数据并行数据流的计算,特别是作为多路连接的输入图形边缘列表上。他们证明了最坏情况最优连接 (WCOJ) 算法可能是一个强大而有效的实现选择。随后,在软件研究了这个模型后不久,硬件人员就跟进了TrieJax架构。
不幸的是,这两种范式都不是最好的。2019 年,AutoMine的开创性工作通过集合相交和相减操作来表示图挖掘任务,并使用自定义编译器生成专门针对给定模式量身定制的高效执行计划。随着GraphZero和GraphPi中的对称破坏和搜索顺序调度等进一步优化,这种模式感知范式几乎能够与专门设计的、高度优化的算法的性能相匹配。可能最出人意料的是,即使是基于集合的范式的软件实现也能够胜过“像嵌入一样思考”模型的硬件加速设计,使其成为明显的赢家。毫不奇怪,硬件研究人员再次转移了他们的兴趣,并产生了另一种架构,例如作为独立加速器的FlexMiner,作为通用处理器的 ISA 扩展的IntersectX,以及作为内存处理设计的SISA。
面对这种不确定性,我们能做什么
尽管如此,没有人真正知道基于集合的范式是否是图挖掘的最终命运。尽管如此,作为硬件架构师,只要我们了解与具体算法变体无关的内在瓶颈,我们就可以始终相信架构课程中教授的那些经典设计原则(例如,并行化、流水线化、摊销等),并且快速将它们应用于任何新兴模型的加速器设计。
那么图挖掘的基本挑战是什么,可以利用哪些基本原则?首先,图最显着的特征是对大量片外数据的随机存储器访问。由此产生的长时间停顿导致计算资源未充分利用。为了解决这个问题,我们可以从经典架构中汲取灵感,例如多线程处理器和 GPU。虽然直接减少停顿很困难,但我们可以公开足够数量的独立任务,这些任务以分时方式在同一硬件单元上执行,从而容忍长内存延迟并提高资源利用率。
其次,图挖掘工作负载通常表现出简单的计算,但大量的控制和数据管理。例如,我们大多只做顶点 ID 之间的整数比较来实现嵌入扩展、多路连接或设置相交/相减。然而,我们还需要大的片上缓存/缓冲区和复杂的控制逻辑(例如,基于集合的范例需要一个堆栈来管理对树结构执行计划的搜索)。这种观察允许一种提高性能的有效方式,即,使用矢量式处理来分摊处理单元的多个通道上的控制和数据管理开销。
第三,具有幂律分布的现实世界图也可能导致负载不平衡,这对简单并行化方法的有效性提出了挑战。一种潜在的解决方案是揭示多个级别的并行性,这样即使一个级别表现出不平衡,其他级别仍然可以很好地工作。这类似于一个强大的内核与许多弱小的内核的争论:当应用程序没有很好地并行化为多个线程时,您仍然需要一个强大的具有高单线程性能的乱序内核,而是利用指令每个线程内的级并行性。
实际上,上述理念导致了在图挖掘中利用多级细粒度并行性的共同见解。这种方法的一个例子是我们最近的工作FINGERS,它使用伪 DFS 顺序公开足够的独立任务以充分利用资源,并与向量化单元并行计算集合操作。
未来发展方向
事实上,图挖掘这个术语有时会被误用。更严格的定义涉及发现相关(例如,频繁出现的)模式和定位相应的嵌入,而图模式匹配采用给定的模式,只做第二部分。今天的大多数硬件设计主要关注模式匹配,仍然缺乏有效发现模式的直接支持,由于要维护更多的中间状态,这具有挑战性。另一个有前途的算法趋势是近似图挖掘,例如ASAP,它对带有仔细有界误差的嵌入进行概率采样。近似采样还提供了显着的加速,并可能成为算法和硬件之外的另一个优化方向。最后,考虑到图数据上越来越多样化的应用程序,考虑我们是否可以拥有一个统一的架构来同时支持传统的图分析、图挖掘,甚至其他新的人工智能算法,如图神经网络和知识图谱,将会很有趣。